
Gemini 3.1 Pro:2個提示詞指南掌握最新模型
Gemini 3.1 Pro是2026年發佈的高推理旗艦模型,本文透過2個實戰提示詞與官方指南解析,帶你快速掌握最新模型,瞭解有哪些應用場景,和其它AI工具全面比較。
一、 什麼是 Gemini 3.1 Pro?
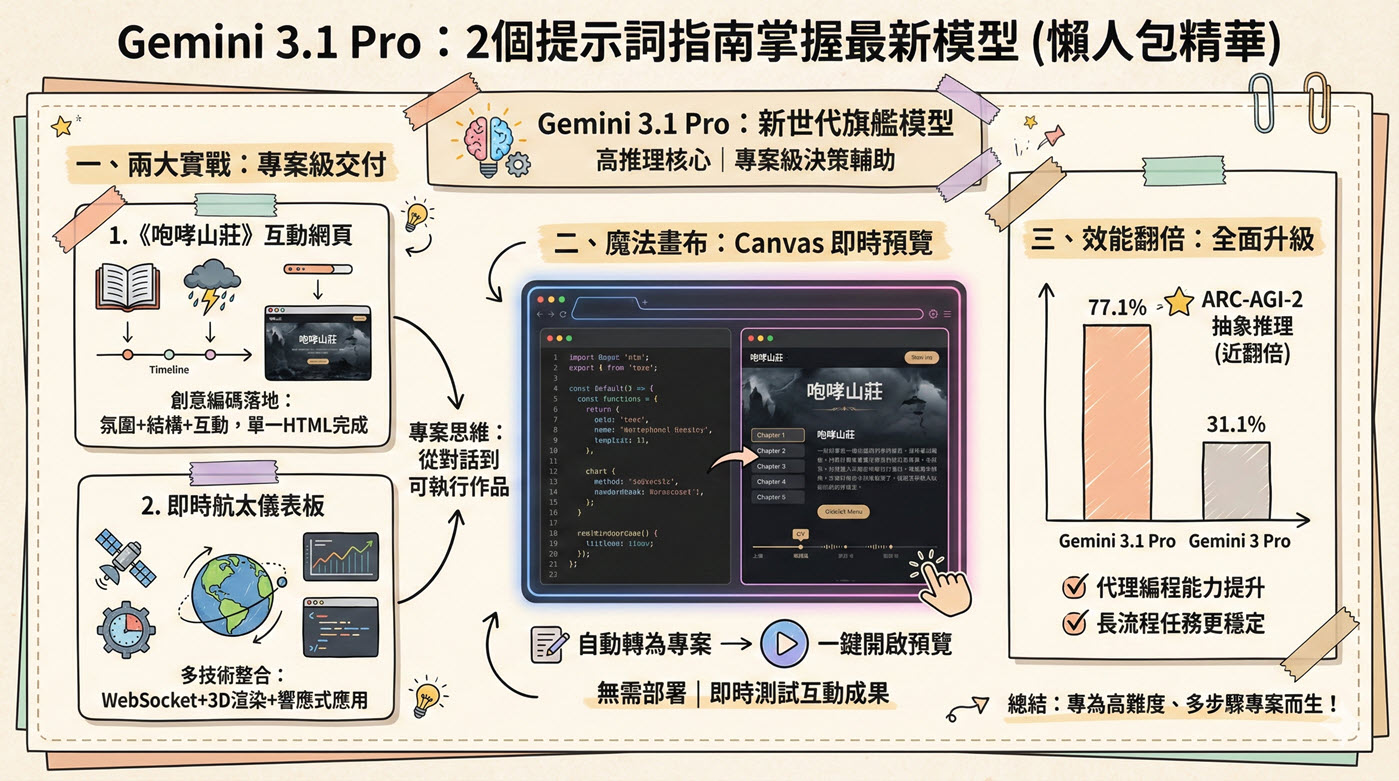
Google 於 2026 年推出的新世代旗艦模型!它不再只是陪聊的機器人,而是進化成「高階專案決策輔助工具」。在評估未知邏輯的 ARC-AGI-2 測試中拿下 77.1% 高分,推理能力直接翻倍!
二、 兩大實戰案例拆解
挑戰:將文學氛圍轉換為單頁網站。
成果:AI 成功消化深色暴風雨視覺、章節與時間軸需求,產出具備完整前端邏輯、滑鼠點擊能順暢開合的無錯位網頁。
挑戰:整合 WebSocket 數據、圖表與 3D 渲染。
成果:成功產出動態資料驅動畫面!滑鼠可拖曳、縮放 3D 地球,軌跡點隨時間更新,展現驚人的專案級整合力。
三、 魔法畫布:Canvas 預覽模式
生成程式碼後,Gemini 會自動將其轉為「專案卡片」。只需點擊開啟並切換至預覽模式,就能直接在聊天視窗右側看見網頁或 3D 渲染結果,無需額外架設環境,即時互動超方便!
四、 效能數據對比
| 關鍵測試項目 | Gemini 3.1 Pro | 前代 3 Pro |
|---|---|---|
| ARC-AGI-2 (抽象推理) | 77.1% | 31.1% (近翻倍成長) |
| Terminal-Bench 2.0 (代理編程) | 68.5% | 56.9% |

一、Gemini3.1Pro:能力翻倍的新世代模型
2026年2月,Google正式發佈Gemini 3.1 Pro,定位為面向高複雜度任務的新世代旗艦模型。一般使用者在Gemini App與NotebookLM中即可直接使用,無需額外部署或技術門檻。從官方公布數據來看,在評估模型解決全新邏輯模式能力的ARC-AGI-2基準測試中,3.1Pro取得77.1%的驗證分數,推理表現超過3Pro的兩倍。這代表模型不只是回答更流暢,而是在「未知邏輯結構」面前仍能建立推理鏈條並完成解題。
這樣的成績透露出Google的企圖心:Gemini 3.1 Pro不是小幅迭代,而是要進入更接近通用智能推理的領域。從聊天回應到複雜專案規劃,從單點回答到長任務整合,Google明顯希望把模型推向「高階決策輔助工具」的位置,而不只是生成內容的助手。
關於Gemini 3.1 Pro,可以參考Google官方介紹文章:Gemini 3.1 Pro: A smarter model for your most complex tasks,裡面有提供示範提問詞,本文即參考官方範例實際操作。
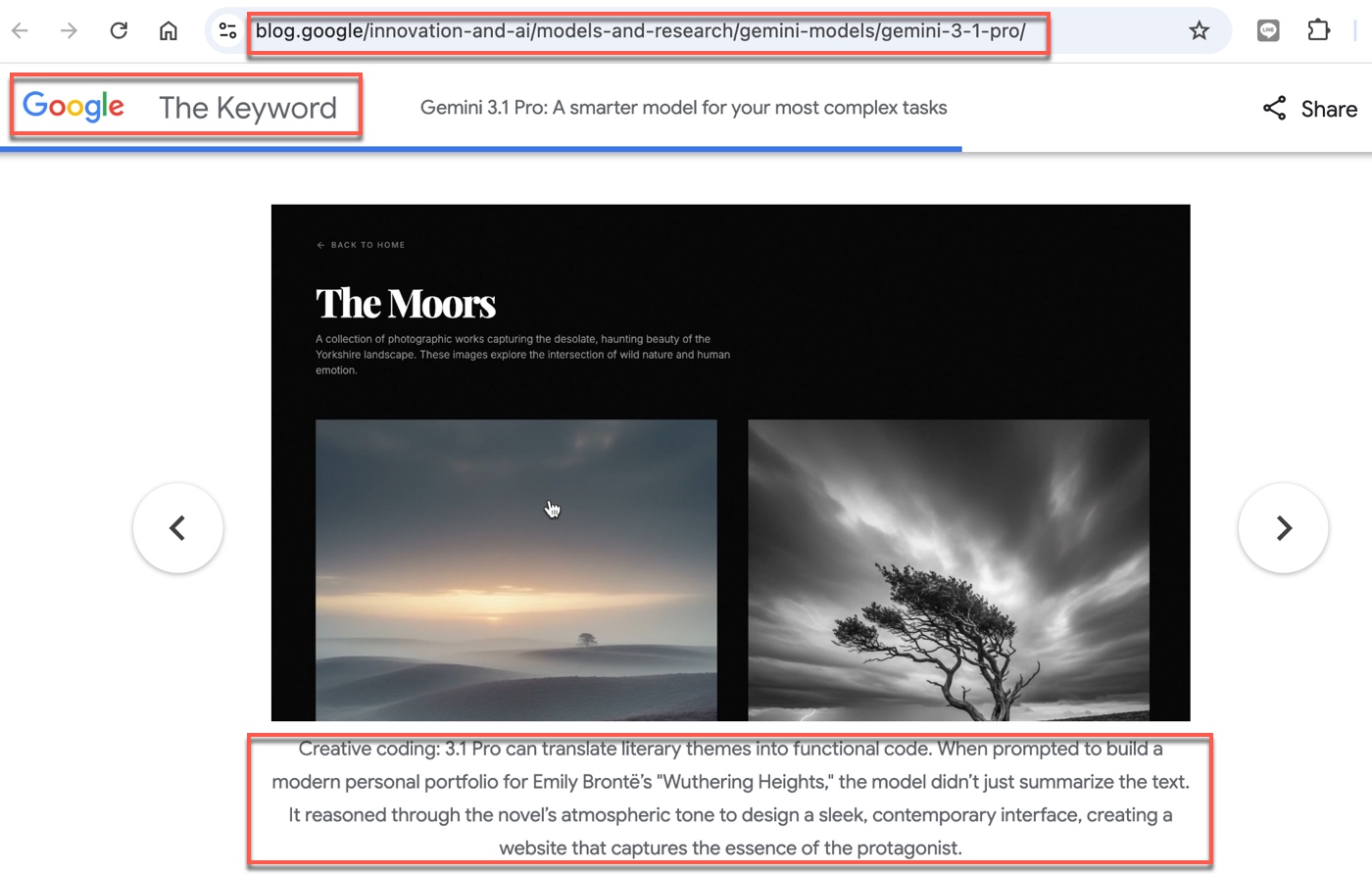
二、《咆哮山莊》互動網頁:參考官方指南範例
在此參考上個步驟Google官方指南範例設計的,目的就是用同一個題目測試Gemini3.1Pro的「Creative Coding」能力是否真的能落地成完整作品,具體提問如下:
「為艾米莉·勃朗特的《咆哮山莊》建立一個單頁互動式網站。
要求:
1. 捕捉小說的陰鬱、浪漫氛圍
2. 使用深色配色方案與暴風雨般的視覺元素
3. 包含章節摘要、角色介紹和作者簡介
4. 加入互動式時間軸
5. 所有代碼放在單一 HTML 檔案中請生成完整的 HTML、CSS 和 JavaScript 代碼。」
這裡的操作可以明顯感受得到:希望AI產出的不是「教學片段」,而是「可執行的單頁作品」。從深色配色、暴風雨視覺元素到章節與時間軸的互動結構,整體更像一套專案需求,而不是單純把HTML、CSS、JS各寫一段就結束。對內容創作者或想快速做Demo的人來說,這種「一次生成可跑成果」的可能性,就是Gemini3.1Pro最有感的實用差異。

三、複製與執行單頁HTML檔案
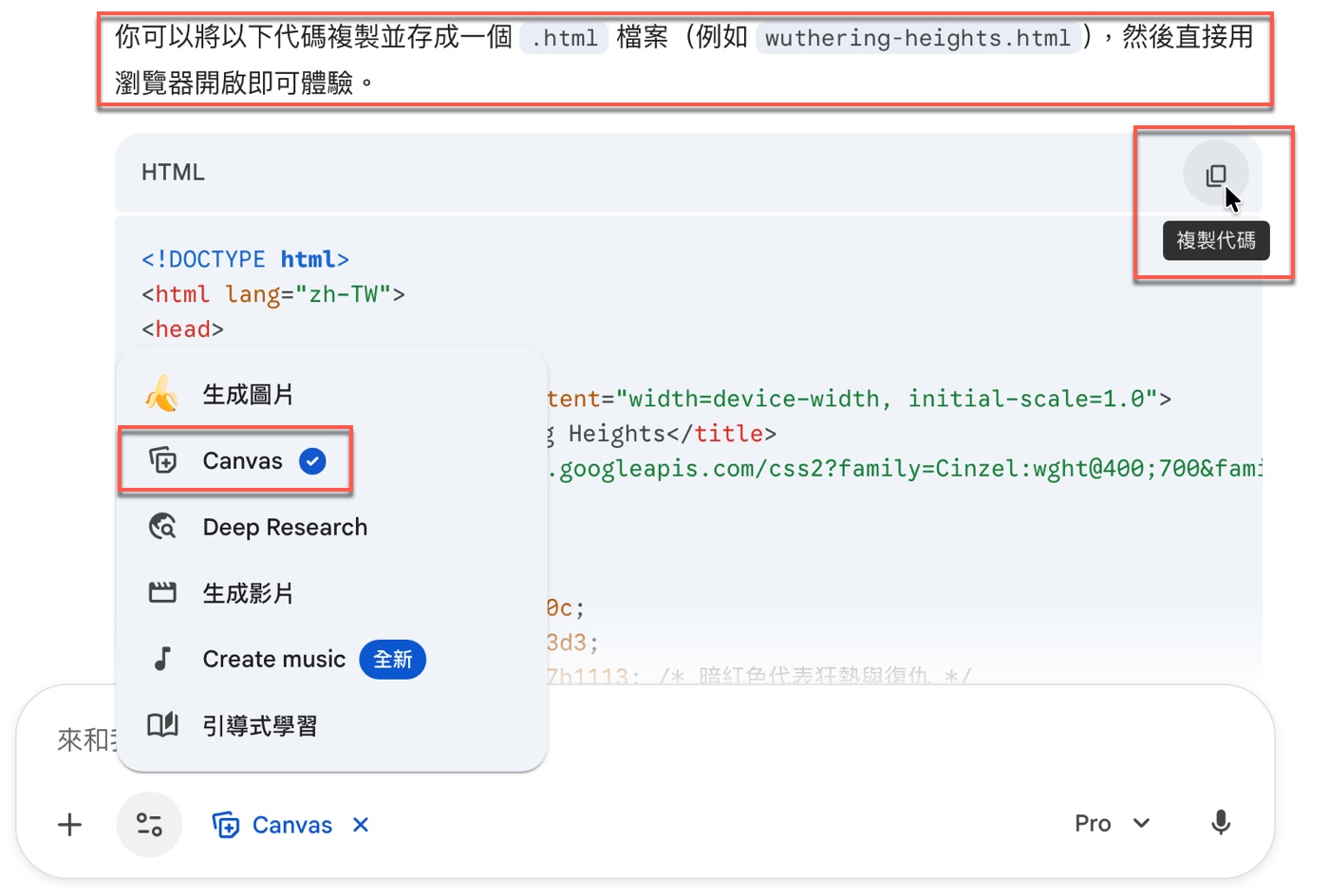
生成代碼之後,Gemini提示可將代碼複製為.html檔案並直接開啟。具體的操作流程,應該是先到右上角「複製代碼」之後,開啟一個空白記事本,複製貼上,另外為HTML檔案,便可以用瀏覽器打開,看到完整互動效果,包括動畫與時間軸等功能。
不過Gemini本身其實就有程式預覽功能,下拉工具清單選擇其中的「Canvas」。
四、轉換為專案檔案:Canvas的關鍵步驟
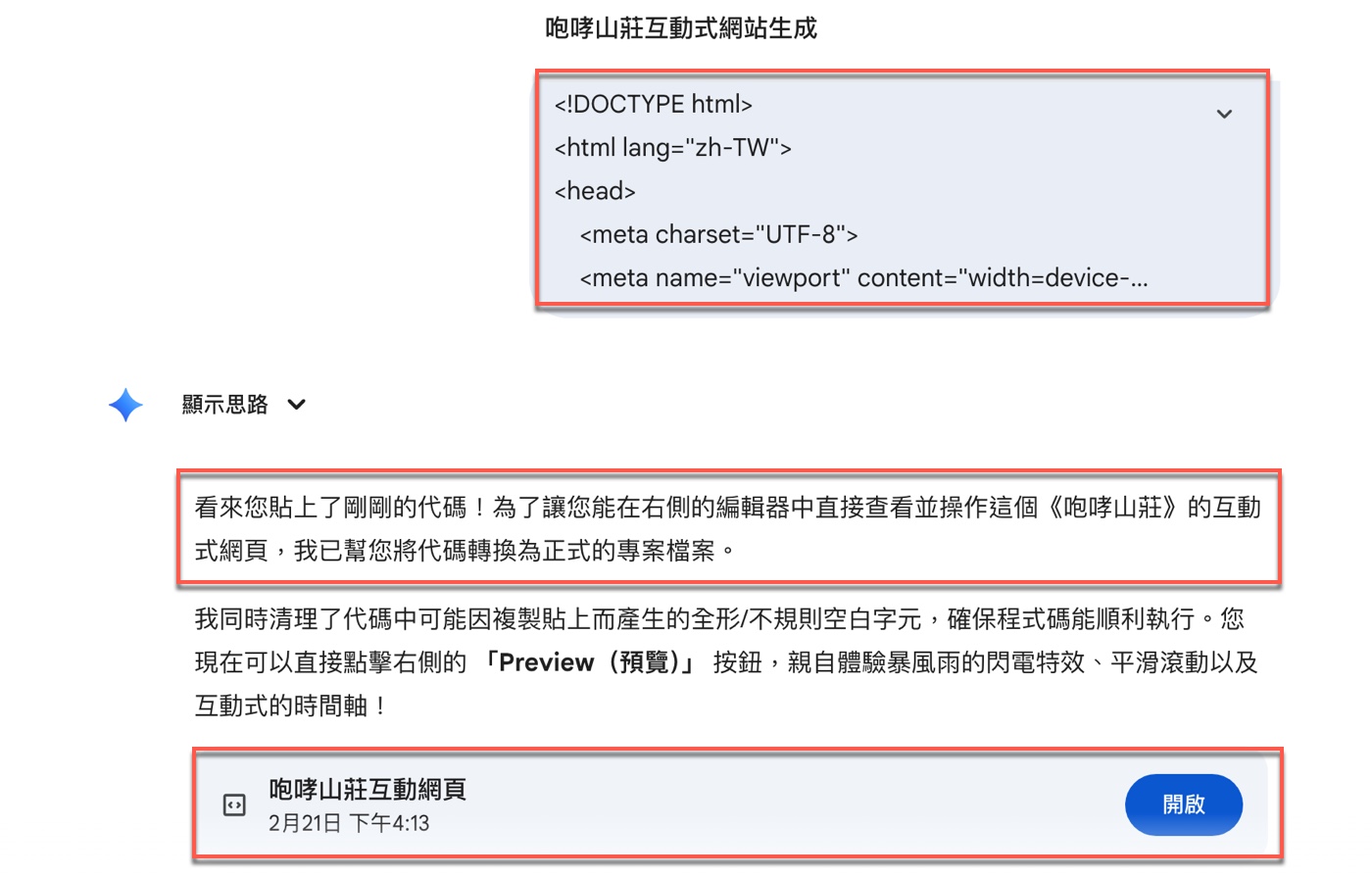
當你將剛剛生成的HTML代碼貼回對話框後,Gemini會自動辨識這是一份完整網頁專案,回應道:「看來您貼上了剛剛的代碼!為了讓您能在右側的編輯器中直接查看並操作這個《咆哮山莊》的互動式網頁,我已幫您將代碼轉換為正式的專案檔案。」最下方則會出現一個專案卡片「咆哮山莊互動網頁」,右側有「開啟」按鈕。
這一步非常關鍵。因為它代表Gemini不只是顯示程式碼,而是將代碼轉換成可執行專案。這裡還沒有正式預覽畫面,但已經完成專案化處理。也就是說,從「聊天生成內容」進階成「建立可預覽專案」,這其實才是Canvas模式真正的起點。
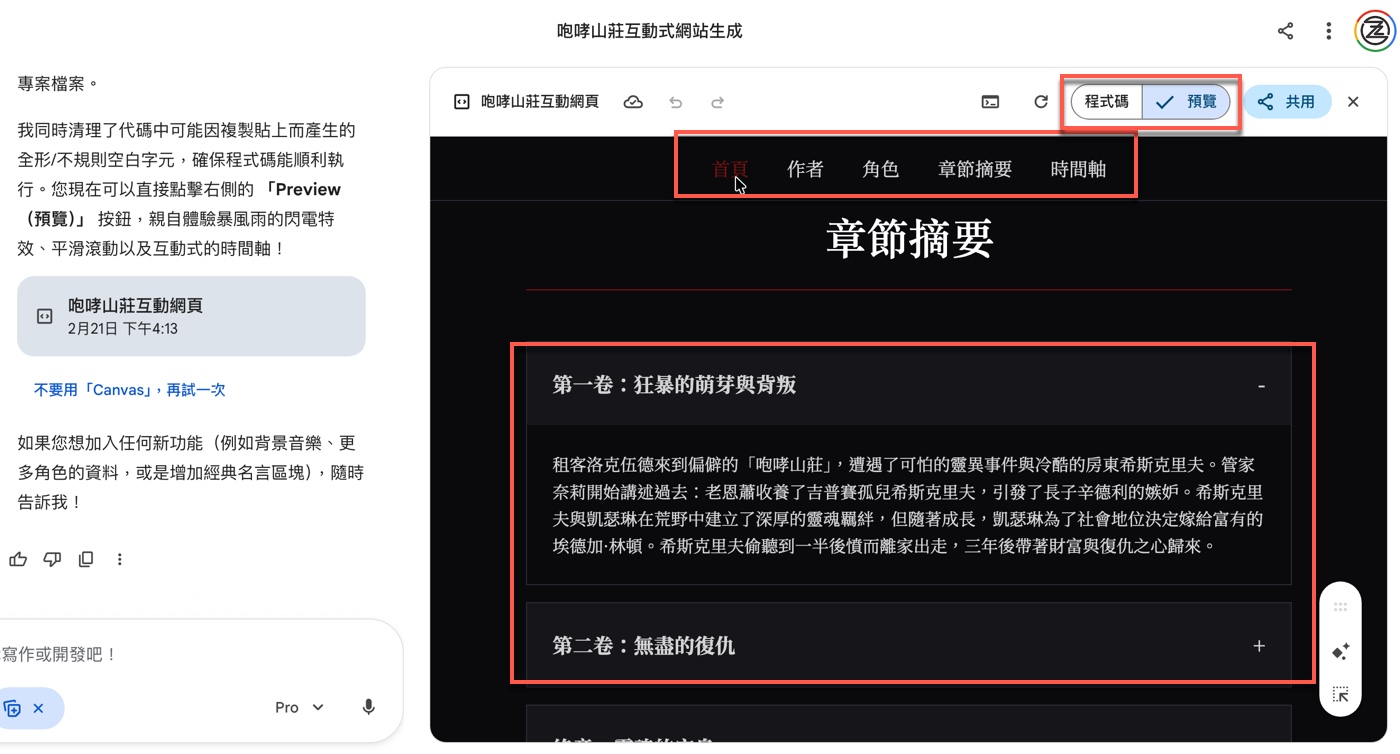
五、Canvas後切換預覽模式的互動測試
點擊上個步驟出現的「開啟」按鈕後,會進入專案編輯畫面。右上角可以看到「程式碼」與「預覽」兩個按鈕,請先確認已切換到「預覽」模式。畫面上方會出現導覽列,包含「首頁、作者、角色、章節摘要、時間軸」等選單。此時可以依序點擊導覽列,確認頁面是否能正常切換。接著在章節摘要區塊中,點擊「第一卷:狂暴的萌芽與背叛」或「第二卷:無盡的復仇」,觀察是否會展開與收合內容。
這一步的重點在於驗證「互動是否成立」。如果導覽列能正常切換、章節能開合、畫面沒有錯位或報錯,代表這已經不是靜態排版,而是完整的前端行為邏輯。從這個畫面可以很明顯看出,Gemini3.1Pro交付的是可操作網頁,整體設計感很強很完整,而不是單純生成文字與樣式而已。
六、即時航太儀表板應用:專案級提示詞設計
接下來同樣是Google官方指南範例,顯然是刻意提高難度,不再只是做視覺排版,而是測試Gemini 3.1 Pro是否能處理「多技術整合型專案」。因此提示詞的思考方式是:同時鎖定資料來源、圖表呈現、3D渲染與前端架構,並明確指定使用的技術工具,讓AI知道這不是概念示範,而是可實作系統。具體提問如下:
「建立一個即時航太儀表板應用:
功能需求:
1. 使用 WebSocket 接收模擬的衛星遙測數據
2. 顯示: – 軌道高度圖表 – 速度儀表 – 溫度監控 – 3D 地球軌跡可視化
3. 使用 Three.js 進行 3D 渲染
4. 使用 Chart.js 進行數據圖表
5. 響應式設計請生成完整的單頁應用代碼。」
從這段提示詞本身就可以看出Gemini 3.1 Pro專案思維。它同時定義了資料流(WebSocket)、視覺層(Chart.js)、3D層(Three.js)與最終交付形式(單頁應用)。這種寫法其實是在設定「交付標準」,而不是請AI示範技術。也就是說,在還沒看到成果之前,我們就已經透過提示詞把任務難度推到系統級整合,這正是測試Gemini3.1Pro專案能力的關鍵。

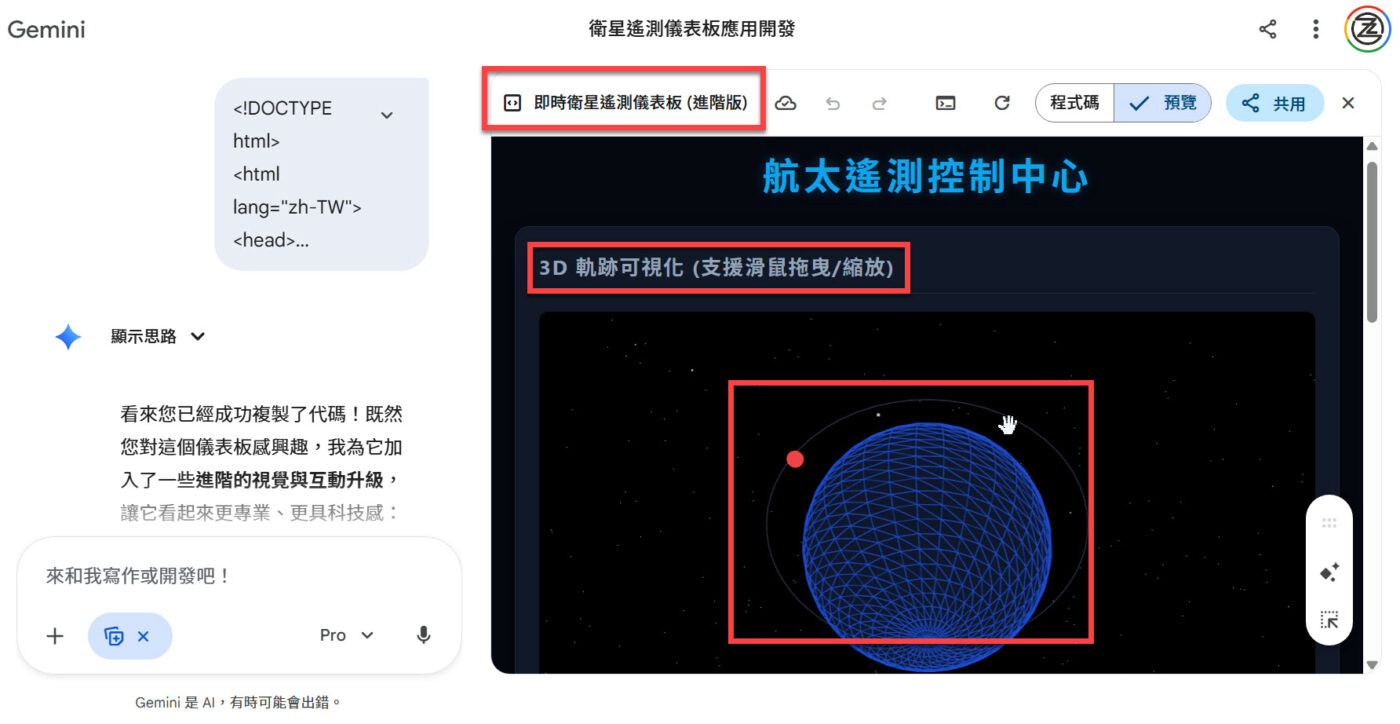
七、開啟進階版專案並測試3D軌跡可視化
當專案生成完成並點擊「開啟」後,畫面上方會出現專案名稱「即時衛星遙測儀表板(進階版)」,代表Gemini 3.1 Pro已將儀表板正式轉為可操作專案,而不是單純程式碼區塊。進入預覽模式後,可以看到區塊標題「3D軌跡可視化(支援滑鼠拖曳/縮放)」,下方則是完整的3D地球畫面。此時請實際用滑鼠拖曳地球模型,測試是否可旋轉視角,並使用滾輪縮放畫面。同時觀察紅色軌跡點是否沿著軌道移動。
這一步的重點在於確認「資料與視覺同步運作」。如果地球模型可以拖曳、縮放,而紅色軌跡點會隨時間更新,代表Three.js渲染與模擬數據流已成功整合。這已經不是靜態3D展示,而是動態資料驅動畫面。對於測試Gemini 3.1 Pro是否具備多技術整合能力來說,這一幕其實就是最直接的驗證結果。
八、Gemini 3.1 Pro特色:兩個實測案例心得
把前面實際操作的兩個題目放在一起看,你會很直觀感受到Gemini 3.1 Pro的「先進」,不僅僅表現在數據多漂亮,而是它很習慣把需求當成專案在處理。
第一個《咆哮山莊》互動網頁題目,提問本身就是把氛圍、視覺元素、內容結構、互動時間軸與單檔交付一次講清楚;第二個即時航太儀表板題目,則是把WebSocket、Chart.js與Three.js的整合需求直接拉到「可跑的單頁應用」層級。這兩個題目做完,開始理解3.1 Pro真正強的地方,是它把高級推理落到可用產出:把複雜主題講清楚、把資料整成單一視圖、把創意做成可執行作品,而不是停在一句「我可以幫你」的聊天層。
再回頭看Google官網指南給的四個示範,其實就像在宣告它的企圖心:
創意編碼(把文學主題轉成可用程式碼)、
動態應用程式開發(把即時資料流做成互動產品)、
SVG動畫設計(把「文字描述」變成可直接上線的動畫資產)、
複雜代理工作流程(把多步任務拆解成能長時間穩定推進的計畫)。
這四個案例不只是展示「我能寫程式」,而是展示「我能把抽象需求轉成完整交付」,而且是同一個模型在不同類型的高難度任務中都維持完成度與一致性,這就是Gemini 3.1 Pro的野心與技術成熟度所在。
九、全面對比:Gemini 3.1 Pro是否真的更強?
如果只看自家版本比較,Gemini 3.1 Pro相較於Gemini 3 Pro的提升其實非常具體,並非體感優化,而是核心推理與代理能力的全面進步。關鍵指標如下:
(一)Gemini 3.1 Pro vs Gemini 3 Pro
從數據可以看到,最大幅度成長來自ARC-AGI-2抽象推理測試,幾乎翻倍提升。這代表模型在「未知邏輯規則」下的推理能力顯著進步。而代理型編程與競賽型程式能力也同步提高。這些指標,其實正好對應前面兩個實測專案中所感受到的「多模組整合穩定度」與「長流程任務維持能力」。
| Benchmark | Gemini 3.1 Pro | Gemini 3 Pro | 差距 |
|---|---|---|---|
| ARC-AGI-2(抽象推理) | 77.1% | 31.1% | +46%(近翻倍) |
| GPQA Diamond(科學知識) | 94.3% | 91.9% | +2.4% |
| Terminal-Bench 2.0(代理編程) | 68.5% | 56.9% | +11.6% |
| SWE-Bench Verified | 80.6% | 76.2% | +4.4% |
| LiveCodeBench Pro(Elo) | 2887 | 2439 | +448 |
(參考Google實測文章:Gemini 3.1 Pro Best for complex tasks and bringing creative concepts to life)
(二)Gemini 3.1 Pro vs ChatGPT / Claude
若與目前主流模型對比,在多項高難度測試中,Gemini 3.1 Pro也展現明顯競爭力:
| Benchmark | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.2 |
|---|---|---|---|
| ARC-AGI-2 | 77.1% | 58.3% | 52.9% |
| SWE-Bench Verified | 80.6% | 79.6% | 80.0% |
| BrowseComp(代理搜尋) | 85.9% | 74.7% | 65.8% |
| MCP Atlas(多步驟工作流) | 69.2% | 61.3% | 60.6% |
| MMMU Pro(多模態理解) | 80.5% | 81.0% | 79.5% |
可以看到,在「抽象推理」「代理搜尋」「多步驟工作流」這三個關鍵面向,Gemini 3.1 Pro明顯領先;在多模態理解與代理編程任務上,則與Claude、GPT接近或持平。這代表Gemini 3.1 Pro的優勢集中在高推理與長流程整合任務,而不是單純語言生成。
整體來看,Gemini 3.1 Pro確實在技術指標上具備優勢,尤其在Google強調的「當簡單回答不夠時」這一類高難度場景中,更能展現差異。若任務只是日常問答,各模型差距有限;但當需求提升到專案級整合時,這些數據差異才會真正體現在實際使用體驗上。
學會計、學Excel、學習AI工具,歡迎加入贊贊小屋社群。
Claude Code 教學:從安裝到 Excel、PPT 與網頁實戰
Claude Code 教學、ChatGPT怎麼用?、ChatGPT Excel教學、ChatGPT寫ExcelVBA、Gemini是什麼?、Notion教學、AI對會計的影響。
贊贊小屋AI課程:OpenClaw AI 代理、Codex 網站、Claude Code 實戰、ChatGPT課程、AI工具全攻略、Notion課程。

