
Word VBA教學:1套爬蟲自動化取得資料的範例
Word VBA教學在此提供1套完整爬蟲範例,程式引用瀏覽器下載取得網頁資料,帶你瞭解實務上具體怎麼利用這個特殊工具,能夠依照自己的需求自動化活用。
上一節介紹如何先取得網頁中新聞區塊的文字內容,然後將這內容儲存於Word文件,這兩個步驟都是運用Excel的VBA操作,資料來源為網頁,資料形式為Word,這其中Excel只是過渡工具,於是乎會有個想法,為何不乾脆直接Word取得網頁資料即可?以下具體介紹:
一、Word VBA
在Word編寫VBA代碼如下,本書截至目前為止都是Excel的VBA環境,而其實在Word同樣「Alt+F11」開啓Visual Basic編輯器,也可以於選項中勾選預設好的開發人員頁籤,如此會發現Word和Excel兩者VBE(VBA環境)根本如出一徹!
10~110:這一段的程式碼和前面Excel章節並無差異,因為作用同樣都是取得網頁資料;
120:Excel主要處理數字(但文字亦可)、Word只能處理文字(無法作計算),所以相較於Excel的程式碼,這裡使用了VBA特有的CStr函數,作用是將其他類型的變數轉換成文字;
130~180:Word專屬的編輯語法。「ActiveDocument.Content」指定文件的內容作為對象(物件),「InsertAfter Text:=Articles」是就這個對象下達操作命令(方法),作用為在目前位置後輸入文件,類似地,「InsertParagraphAfter」作用為在目前位置後增加一個新的段落輸入,效果等於直接在Word按「Enter」鍵。

二、Word執行VBA程式
在Word執行「Word_Web」,操作方式和Excel執行巨集相同,快速組合鍵為「Alt+F8」,執行結果非常漂亮。
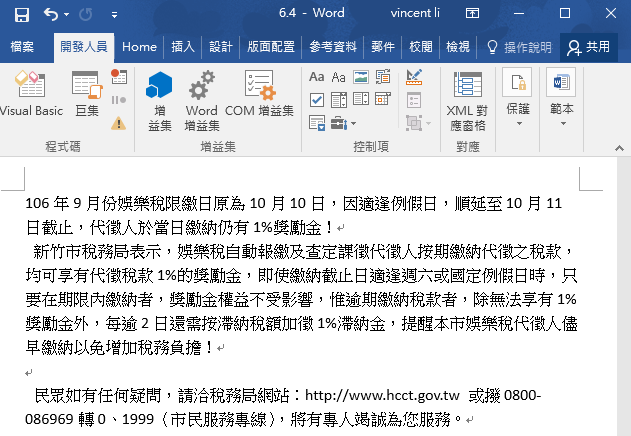
三、新聞彙總網頁
上個步驟是一篇完整的文章,通常新聞類的網站還會有以標題為主的彙總網頁,例如下列新竹市稅務局的稅務新聞。
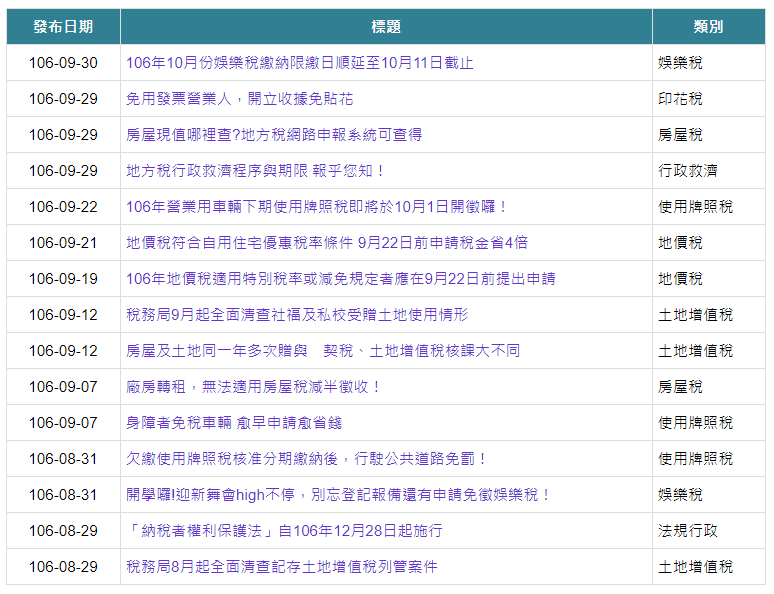
四、HTML DOM結構
取得網頁特定內容的第一步,是瞭解其於整個HTML網頁DOM結構(Document Object Model)的位置,先前都是利用Chrome瀏覽器工具,雖然沒問題,但畢竟網頁原始碼型態上就是一個文字資料,很適合用Word處理,這裡介紹如何用Word的VBA取得網頁原始碼。
110:先前程式碼是取得特定分類名稱的網頁素:「Set news = doc.getElementsByClassName(“ap02”)(0)」,這個則是取得整個網頁的呈現主體:「Set news = doc.body」。

五、Word尋找新聞標題
文章彙總的網頁,每一條標題都是各個單一文章的超連結,利用此特性,於取得首頁「body」的Word文字中,先以瀏覽或關鍵字搜尋的方法,找到新聞標題在Word文件中的位置,選取某一標題的「」,使其標黃色表示選取後,再快速鍵F4搜尋,如圖所示可以得知該標題於HTML DOM中的項次:「第501個結果,共616個」。
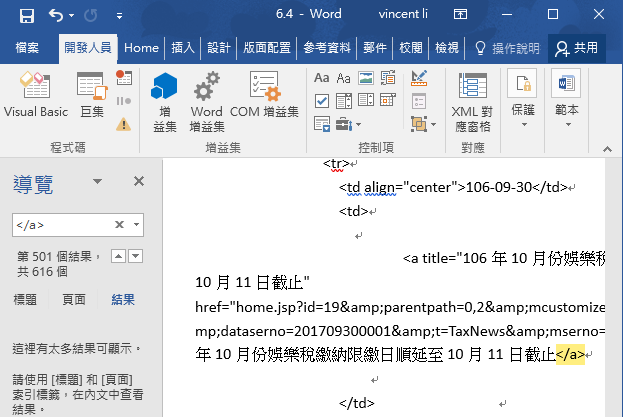
六、Word網路爬蟲程式
以上個步驟得到的資訊為基礎,編寫VBA程式碼如下:
30:定義變數「i」為「500」;
120~180:套用先前章節學到的For~Next」迴圈語句,變數為「j=0 To 14」,再結合「Set news = doc.Links(i + j)」物件定義,等於是依次取得網頁第500到第514的超連結元素。

七、Word網路爬蟲結果
執行「Word_WebLinks」的結果,一如預期。
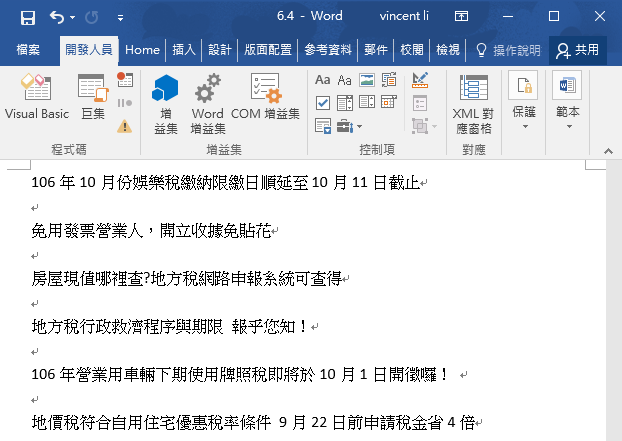
VBA網路爬蟲的關鍵字
在本章第二節第七步驟,介紹過VBA想取得網頁的某特定部份,有許多關鍵字類型可使用,先前章節一直都是藉助「getElementsByClassName」,這一節用到了「body」及「Links」,相信經過這三個具體的範例操作,讀者應能舉一反三,在有需要的時候引用其他的關鍵字工具。
贊贊小屋VBA教學中心:
Excel巨集執行、Excel巨集程式、Excel巨集程式碼、Excel VBA教學、VBA教學、Excel巨集範例、VBA UserForm、VBA VLOOKUP。
VBA課程推薦:零基礎入門進階的20小時完整內容
相關文章:
