
robots.txt規範:3條範例敎學理清楚SEO收錄觀念
robots.txt規範有很多可能的形式,本文以WordPress網站外掛作為教學工具,介紹3條最基本的範例,帶你理清楚它的意義跟作用,學會SEO收錄觀念和搜索引擎優化原則。
一、Rank Math外掛
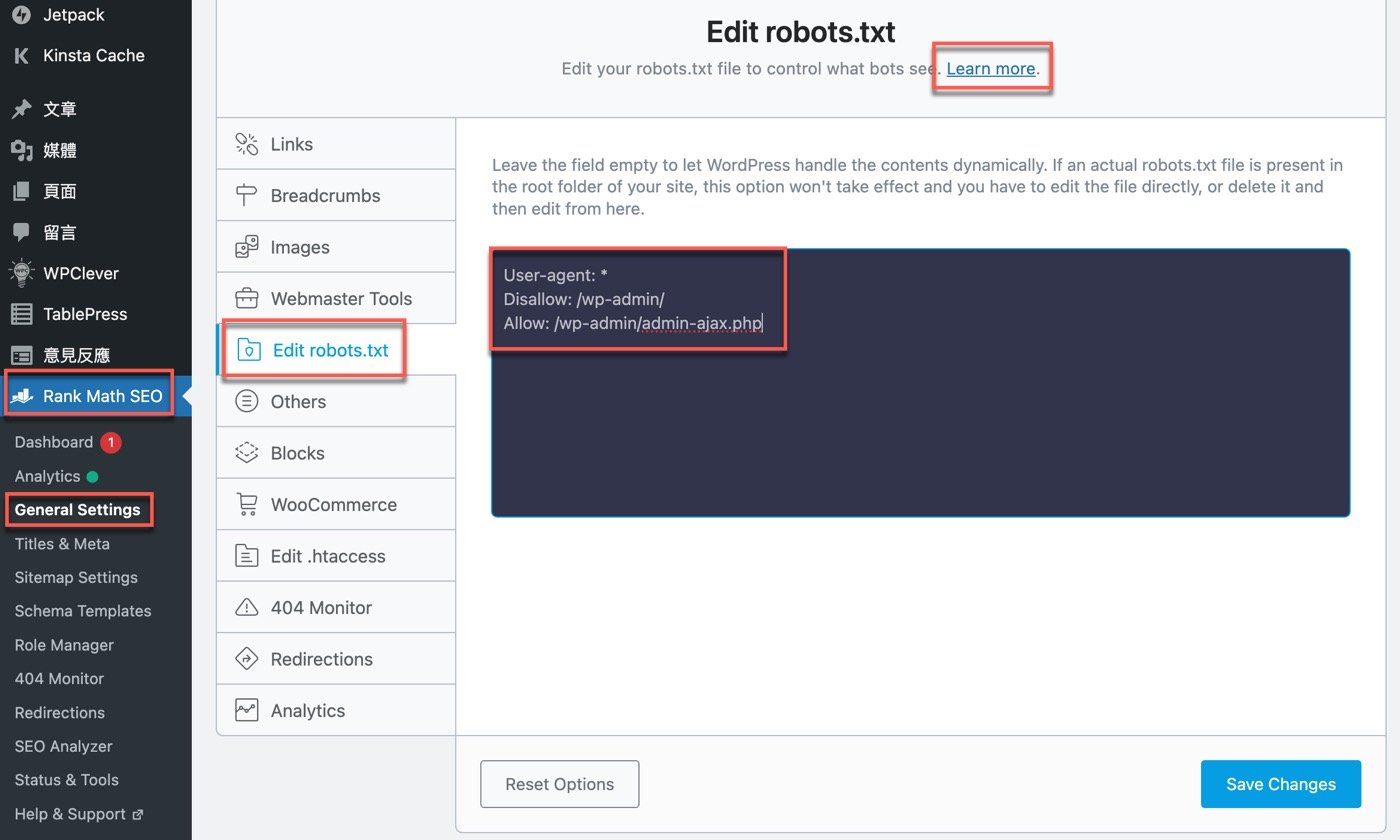
在Wordpress網站安裝Rank Math SEO外掛之後,左邊的側邊欄進入這個外掛的「General Setting」頁面,選擇索引標籤中的「Edit robots.txt」,可以看到目前預設的原始文件內容,點一下有個超連結文字「Learn more」,前往它的說明頁面。
二、robots.txt是什麼
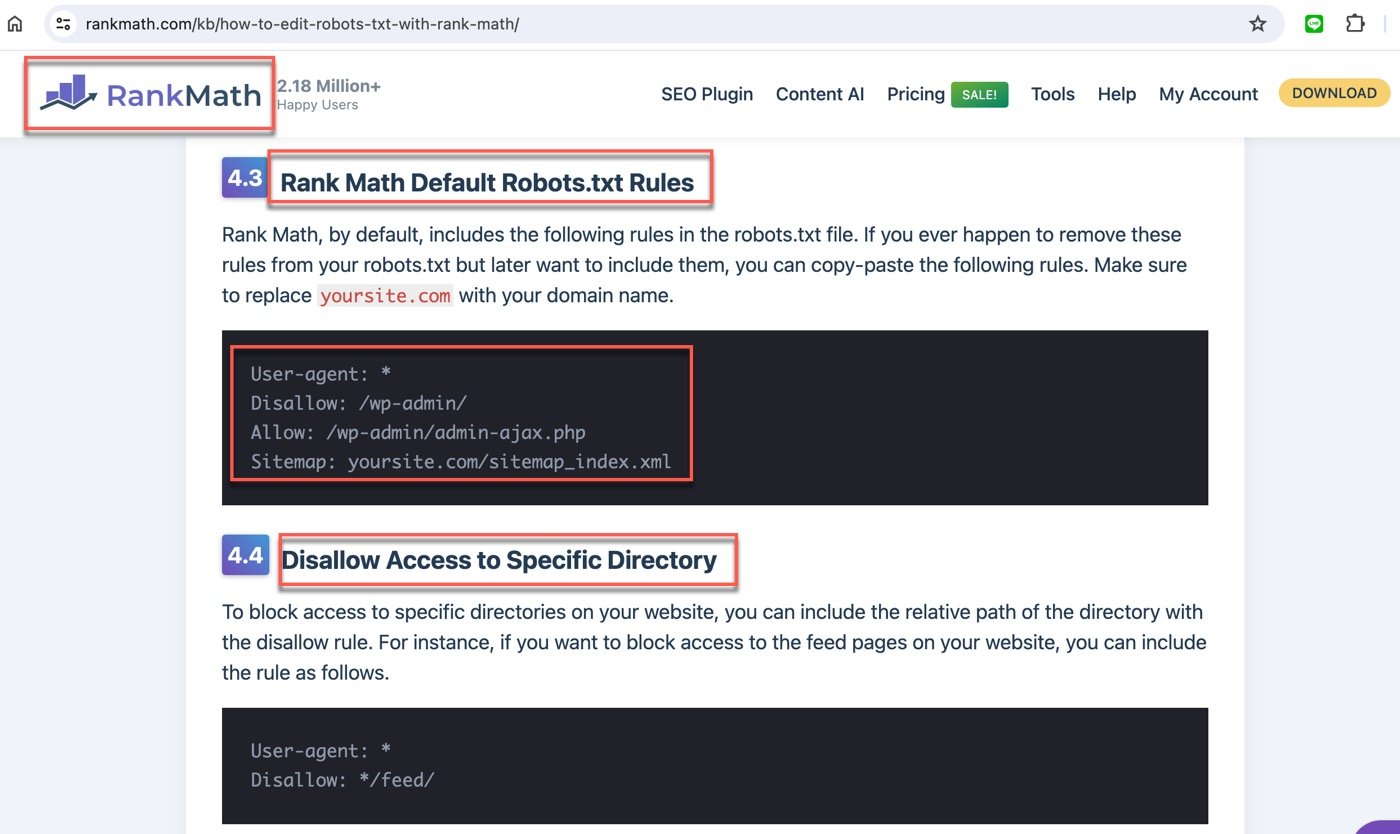
進入說明頁面,這裡有詳細的觀念介紹文字,也有具體設定範例,雖然都是英文,但是從簡單的文字範例可以初步瞭解robots.txt是什麼,它的作用是告訴搜索引擎我的網站上有哪些頁面不希望收錄在查詢結果中,或者反過來,有哪些頁面是允許可以。
可能會覺得允許搜索又不允許搜索似乎有點奇怪,其實網站網頁的結構類似於電腦資料夾,為了方便起見,通常會設定某個資料夾為不允許,同時又可能希望該資料夾中的某個網頁文件例外可以被收錄,這時候就可以用到允許跟不允許的設定。
關於這方面知識,可以進一步參考robots.txt簡介,它是Google提供的說明文件。
三、Chat GPT AI引用
基本瞭解了robot.txt的作用之後,RankMath SEO外掛還有提供蠻多的說明項目,其中有一個跟目前流行的AI模型有關。
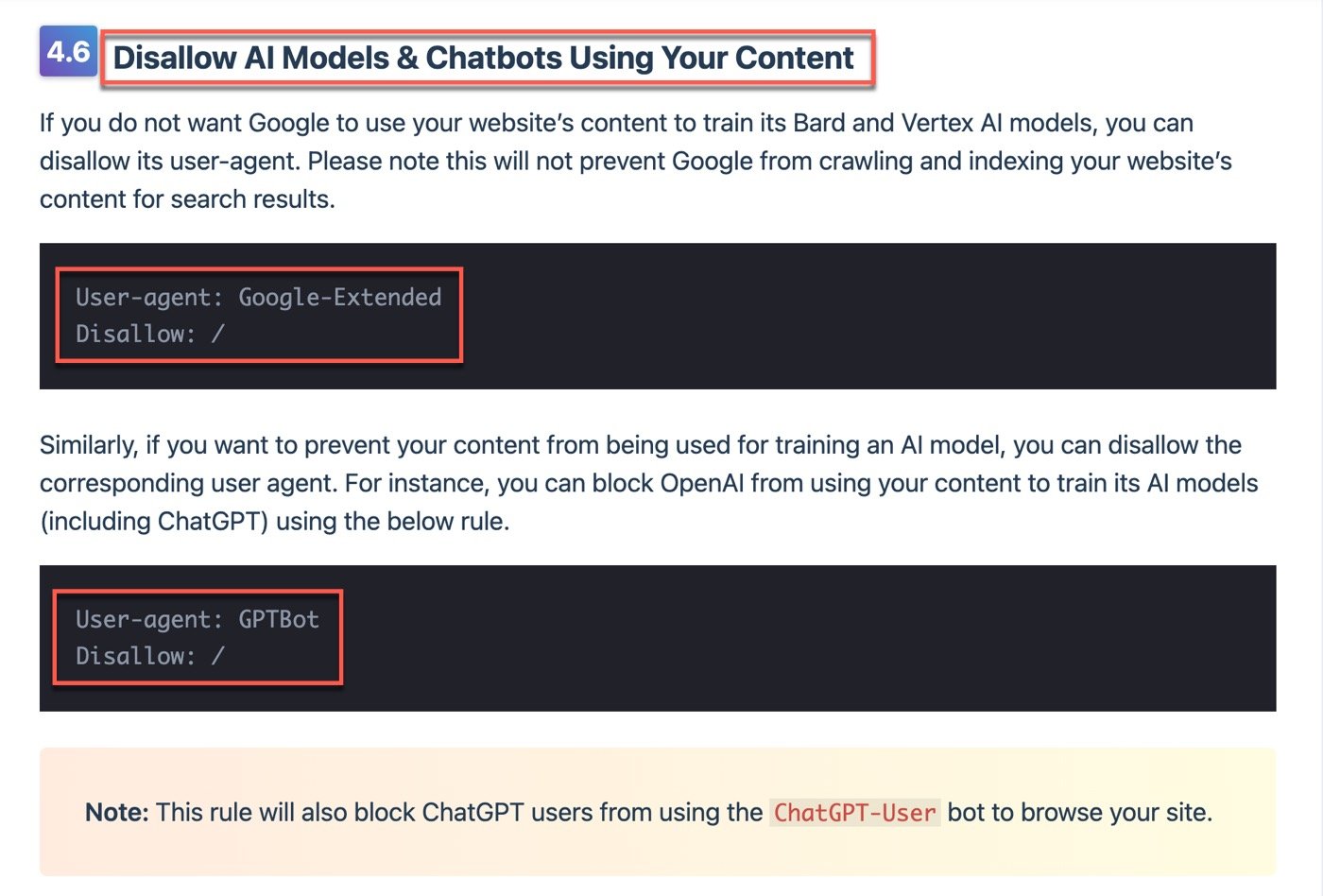
想要瞭解某一件事情,帶著這個搜尋意圖在Google輸入關鍵字,得益於網路資源非常豐富,大部分都能找到想要的答案。ChatGPT AI引用也是類似機制,它取得了網路資料庫種種資訊之後,利用人工智能模型進行重組自動編輯,回應使用者的問題。
這裡面會有是否尊重創作者的問題,因為Google會保留原始內容並且署名作者,但是AI模型等於汲取了所有人在網路所產生的內容,原則上應該經過同意,基於這個概念,可以設定自己網站的內容不希望被收入在AI模型中。
四、robots.txt規範
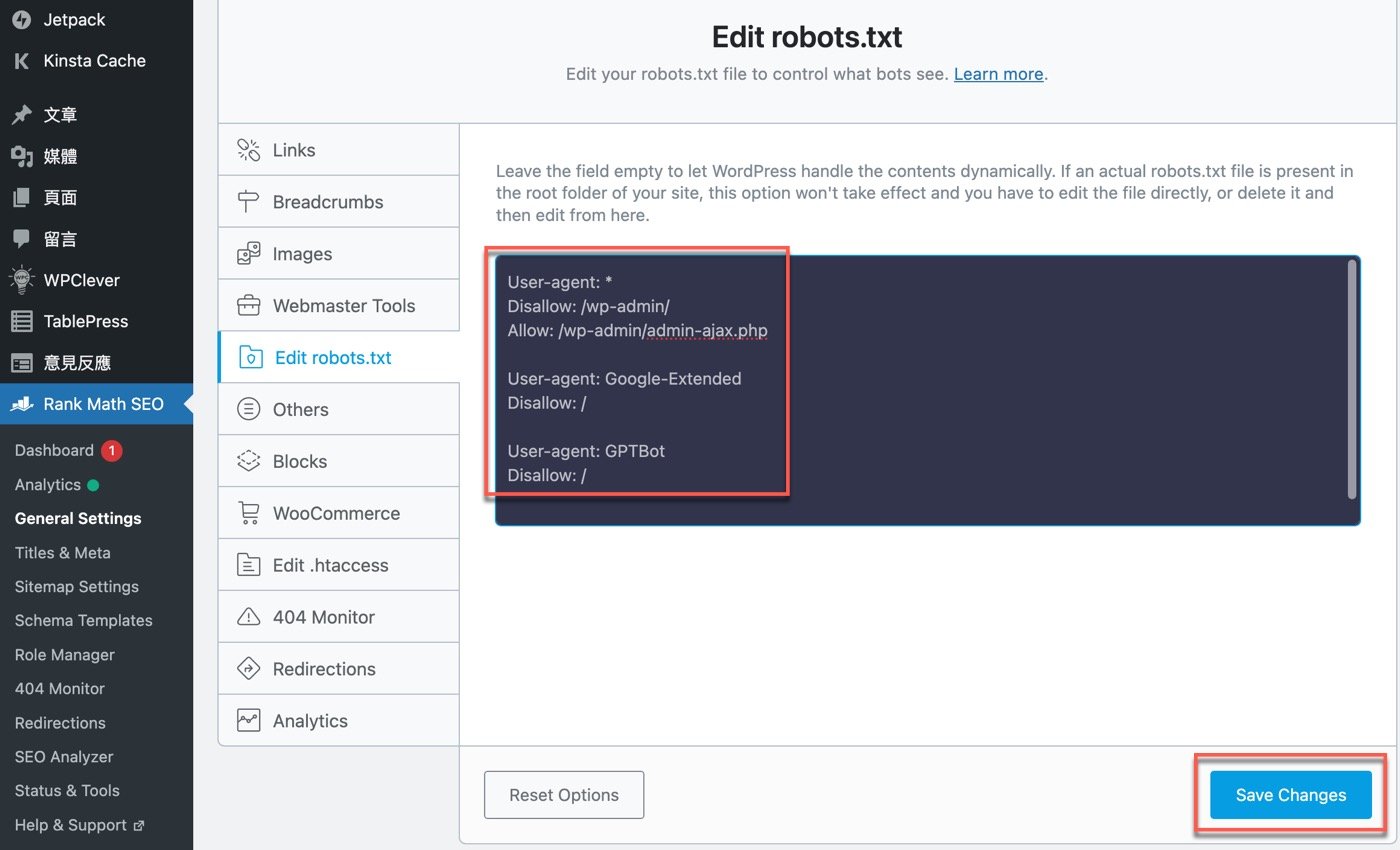
在先前步驟的基礎上,大致對於robots.txt有基本認識,再回到RankMath Seo外掛中編輯robots.txt文件。瞭解相關概念再來看這裡實際的規範內容,會比較能夠瞭解這幾行其實很簡單的英文句子,到底其意義跟作用是什麼?這個過程跟網頁時間查詢一樣, 都是搜索引擎優化學習的紮實功夫。
總結而言,robots txt是什麼?它是在網站上一份專門給搜索引擎看的文件,告訴Google甚至是ChatGPT可以怎麼使用網站上的資料,哪些可以收錄查詢,哪些不能納入使用,因此是SEO必學的基本技巧。
五、Google Search Console
既然在網站已經設定好了robots.txt,而且這是跟搜索引擎有關的操作 經營網站的人對於Google Search Console應該都不陌生,它正是搜索引擎Google為網站的站長們所提供工具。
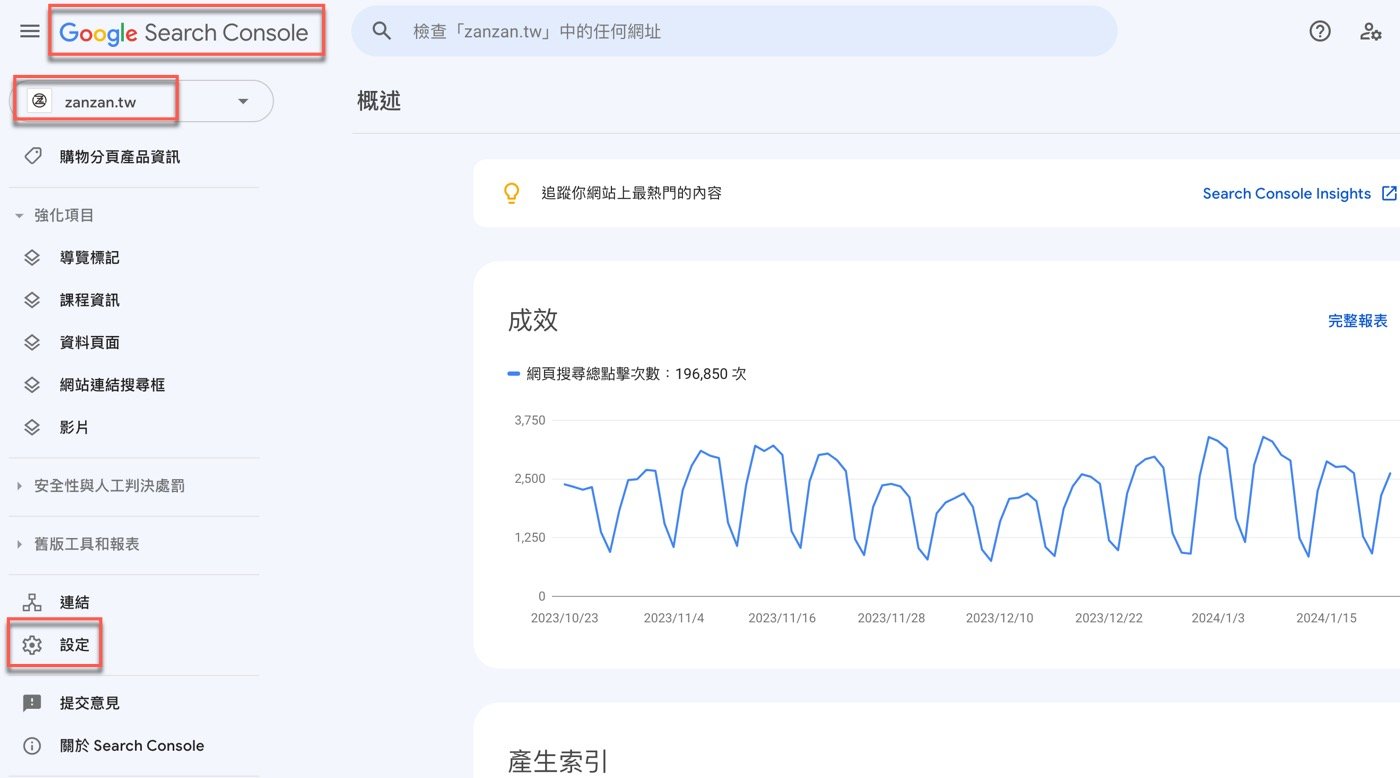
以贊贊小屋自己的網站登入這個平臺之後,在左邊的側邊欄點選齒輪狀小圖標的「設定」。
六、GSC設定工具
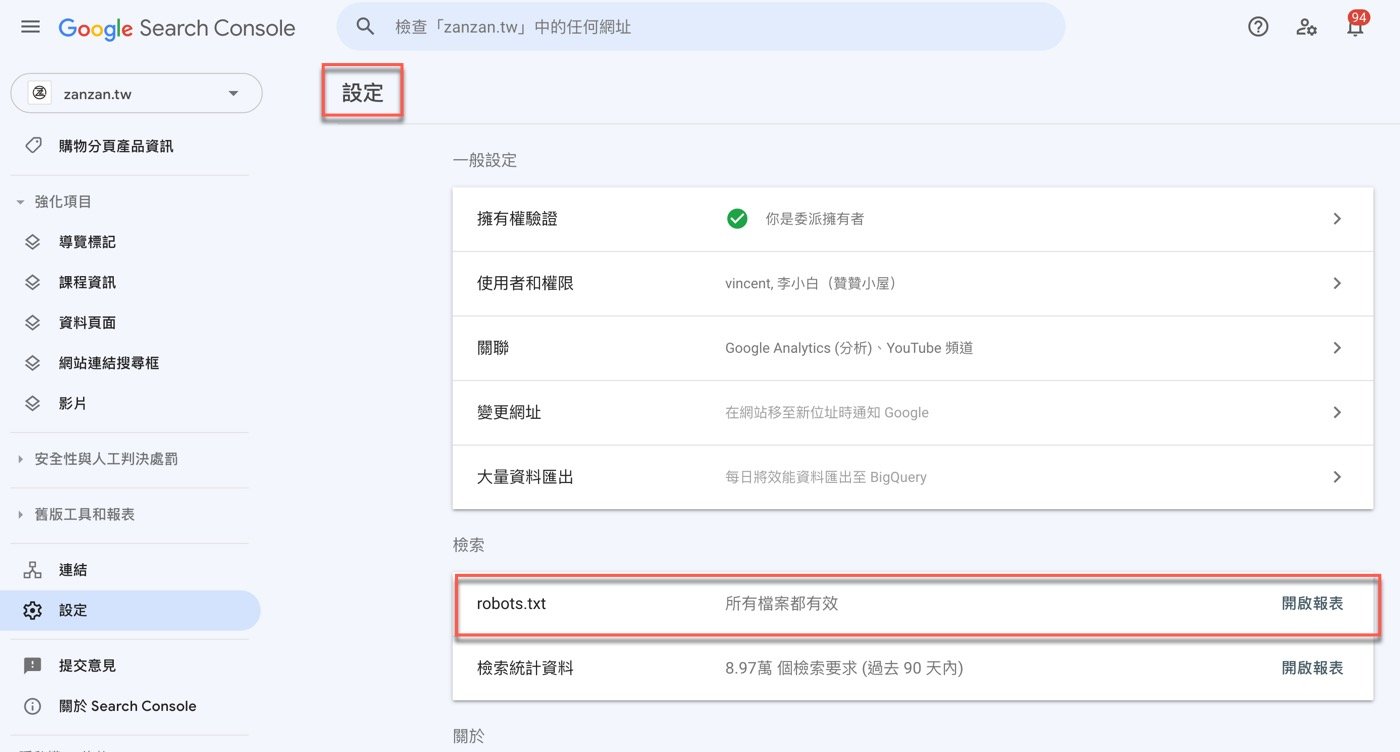
進入GSC設定頁面,從內容大概可以知道這些網站的基本事項,主要目的是提昇Google關鍵字搜尋量,在「檢索」項下有個跟本篇文章主題相關的「robots.txt」,點選右邊的超連結文字:「開啟報表」。
七、要求重新檢索
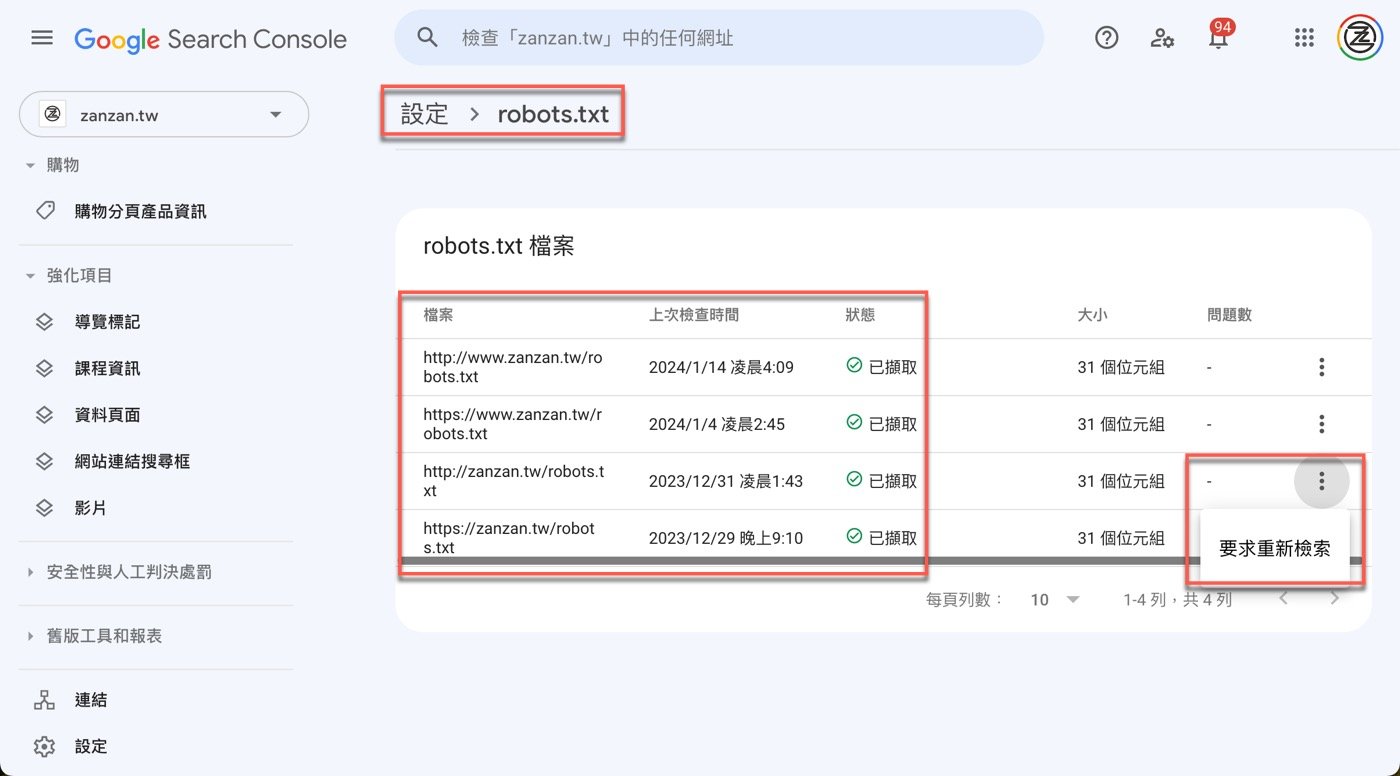
延續上個步驟,開啟報表頁面之後,果然看到Google確實會去讀取網站上 的robots.txt文件內容,每次讀取都有紀錄時間點,點一下右邊三個點的小圖標,會出現「要求重新檢索」的文字按鈕。
附帶一提,Google線上應用的操作都是如此直覺方便好用,讀者有興趣請參考看看Google Pagespeed Insights使用案例,它可以評估網站速度,也是網站經營者一定要熟悉的工具。
八、已擷取檔案內容
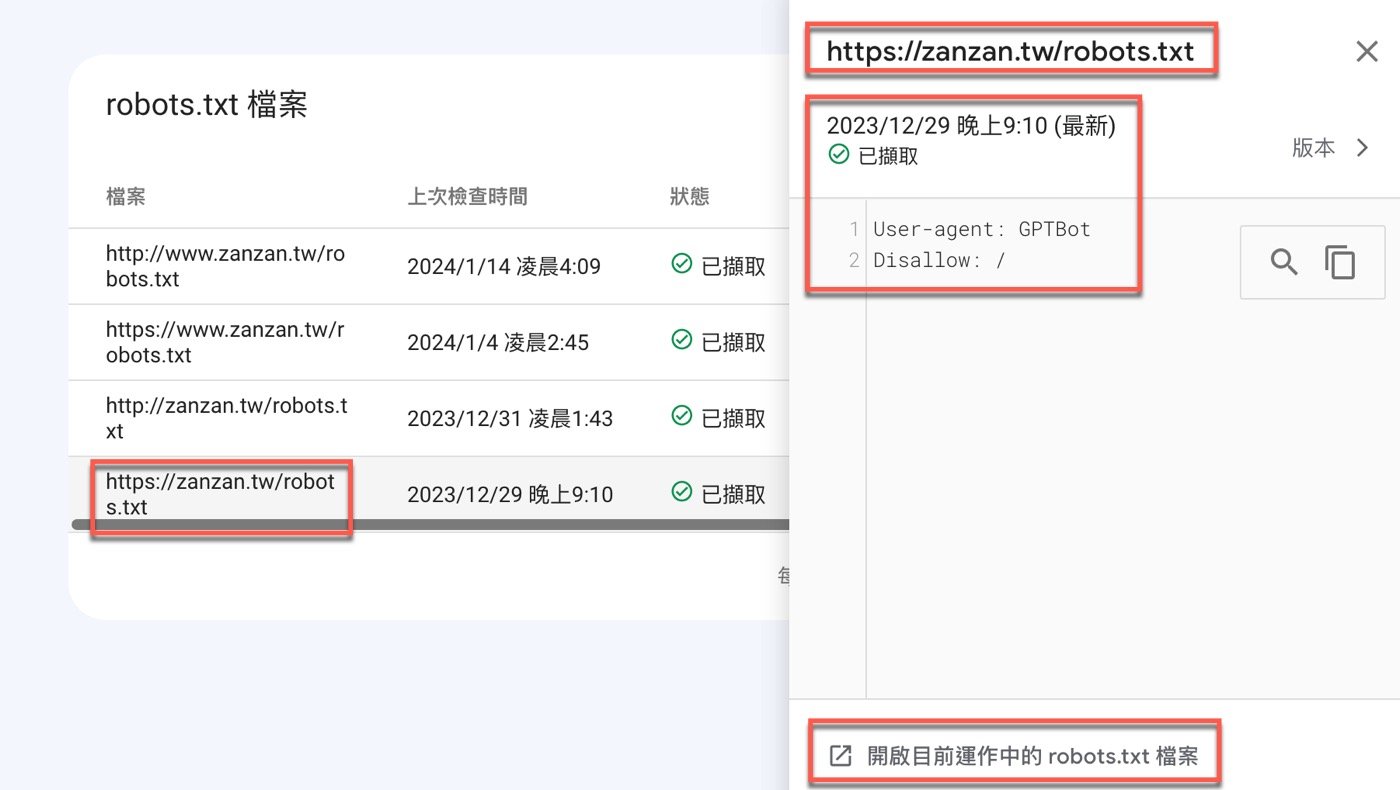
除了重新檢索之外,還可以直接點選每個項目的網址,右側會開啟小視窗,注意到最上方是一個網址,視窗內容是先前第四步驟所設定的檢索條件。從這裡也可以知道,所謂robots.txt是比較公開透明的東西,不像另一個SEO概念關鍵字密度那樣模糊,無絕對標準,在Google Search Console沒有相關功能,只能透過其他工具例如Rank Math外掛進行評估。
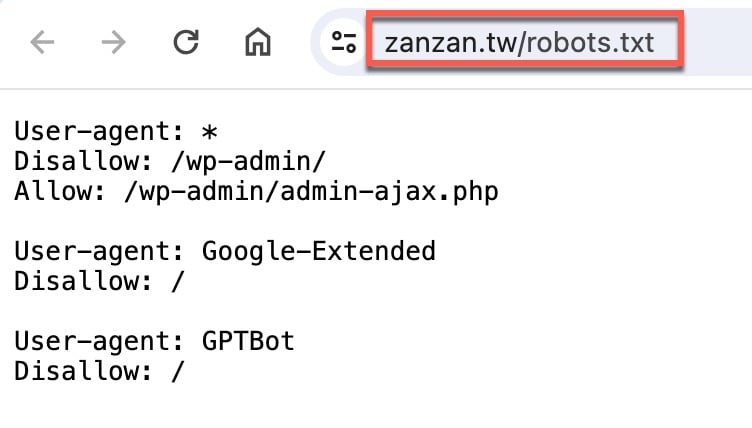
九、HTML網頁文件
既然瞭解了robot.txt其實也是網頁文件,當然可以直接在瀏覽器直前往這個網址,其實就是單純的文字內容,只不過這網頁並非給一般讀者看的,是特地提供給搜索引擎和AI模型閱讀的,就跟結構化資料標記類似用法,robot.txt是決定能否收錄,結構化資料標記是收錄後提升搜尋體驗。
SEO收錄觀念原則
本文瞭解到robots.txt也是一個網頁,似乎會覺得有些奇怪,其實網站的本質原本就是透過HTML呈現內容,只不過一般人是透過瀏覽器解析後閱讀網頁,搜索引擎是直接讀取原始HTML文件。從這個角度理解並延伸,可以得知為何SEO搜索引擎優化會強調一個重點:網頁不但是寫給一般讀者讀,同時也是要給搜索引擎看,robots.txt文件剛好是最佳範例。具備了這個觀念,才能往前再一步,瞭解自己網站的熱門查詢項目,著手規劃種種排行優化的操作。
贊贊小屋SEO教學:
SEO是什麼、PageSpeedInsights教學、Rank Math SEO教學、臉書社群經營、YouTube頻道設定。

相關文章:
