
遭到 robots.txt 封鎖?學會SEO的1個關鍵設定
遭到 robots.txt 封鎖是很嚴重的問題,它表示網頁不會被Google收錄,也因此根本不會出現在搜索結果中,本文以實際Google Search Console操作範例,介紹如何設定這個SEO關鍵文件。
一、Google Search Console涵蓋範圍
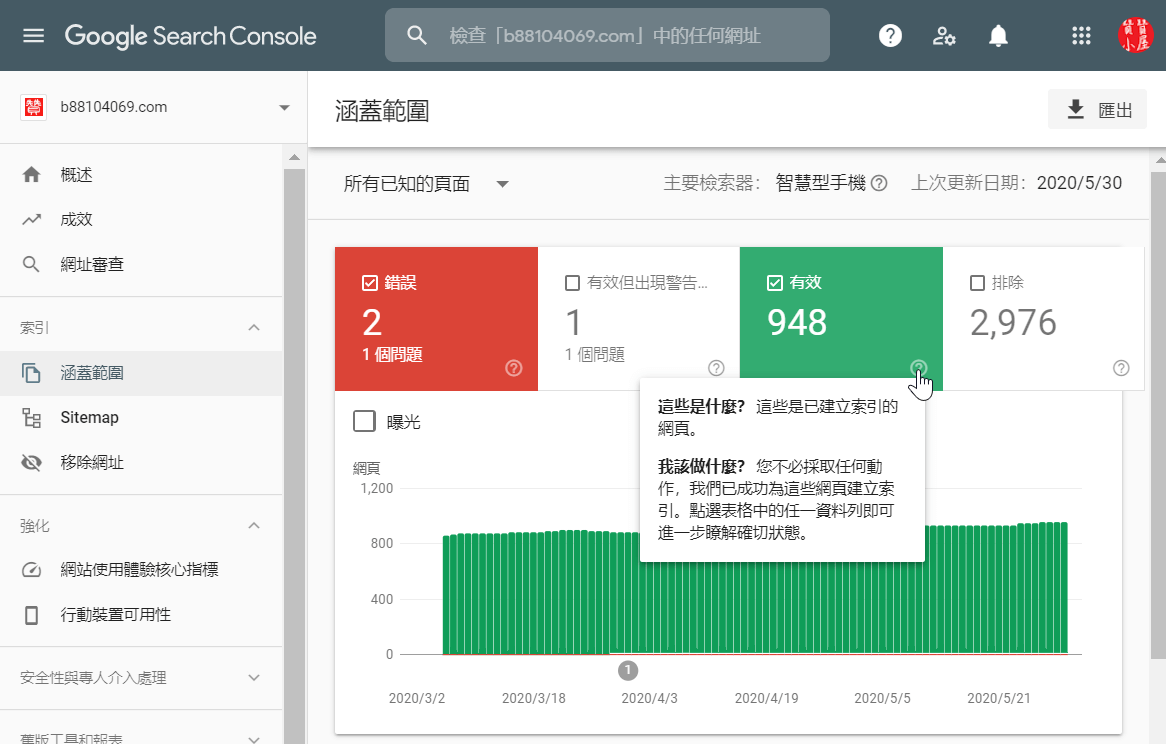
登入Google Search Console之後,左邊欄位選擇「涵蓋範圍」 ,這裡共有四個類別,將游標移到每個類別右下角的問號會有相關說明,其中「有效」指的是Google已經建立索引的網頁,意思是網站有948個網頁文件被收錄在Google圖書館,當有人搜尋和網頁有關的關鍵字,Google會考慮呈現該網頁,網站SEO便是致力於提高被Google選中的機率。
二、詳細資料
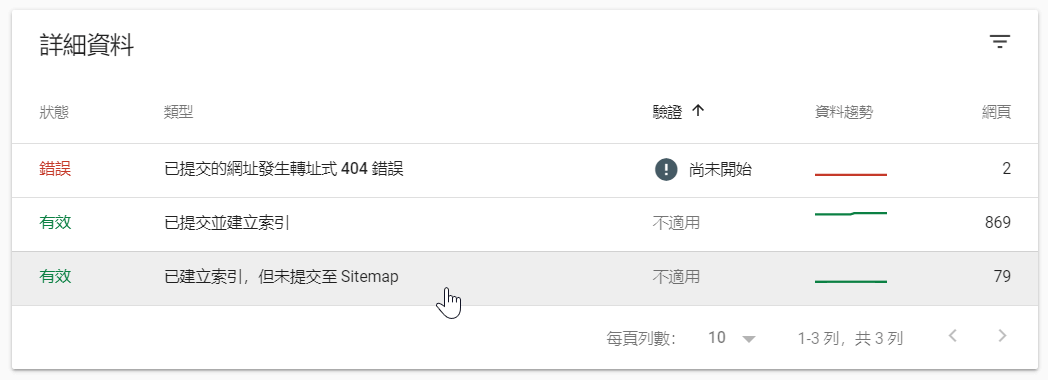
同一頁面下方的詳細資料中,有效狀態的網頁又分成兩個類型:「已提交並建立索引」和「已建立索引,但未提交至Sitemap」。已提交Sitemap意思是自己有寫好一份網頁目錄提交給Google參考。此時我的Wordpress總共有891篇文章,也提交了Sitemap,Google只收錄869,沒有照單全收這倒是可以理解,但是有79篇不在我目錄裡面,Google卻幫我建立索引了,這比較奇怪,為了網站SEO有必要進一步瞭解,點擊進入明細清單。
三、已建立索引,但未提交至Sitemap
看了明細比較清楚。「https://www.b88104069.com/profile」是贊贊小屋網站的介紹頁面,「https://www.b88104069.com/」是網站首面,因為我是利用PHP程式讓Wordpress自動產生Sitemap,只會有文章頁面,這兩個頁面確實會漏掉,Goggle幫忙收錄最好。
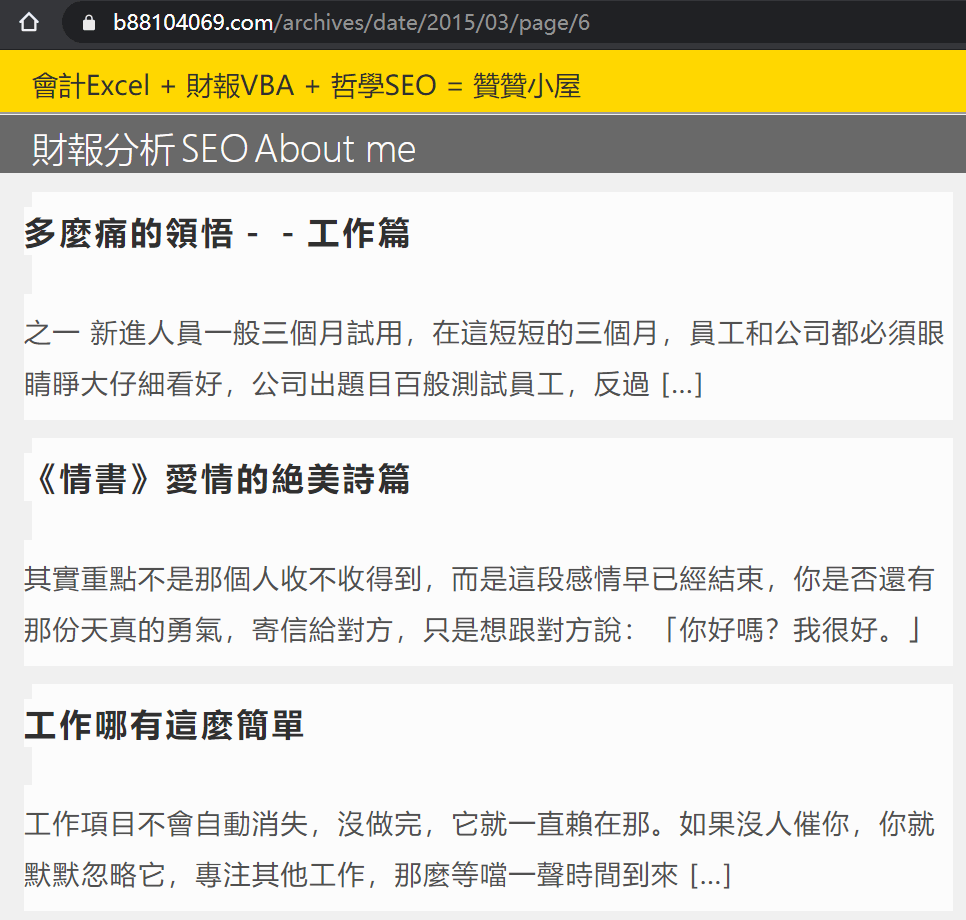
其餘網頁以「https://www.b88104069.com/archives/date/2015/03/page/6」和「https://www.b88104069.com/archives/author/b88104069/page/60」為典型,從網址結構大略可知是依照日期和作者的分頁目錄,日期還有些久遠,這應該我以前有設定過相關網站機制,現在已經不用了,沒想到Google還留著。

四、網站分頁目錄
實際瀏覽網頁,果然和我猜想的一樣,像這樣的網頁目錄頁面其實並沒有全部文章內容,如果真的出現在搜索結果,讀者點進來發現不如預期的話,馬上離開,這個訊息會反饋到Google那裡,Google因此會降低網站分數,對於SEO不是件好事。
五、robots.txt文件
這種事讀者不高興、Google不想要、我當然也不喜歡。為了有效避免,SEO技術中有一種robots.txt文件,可以很清楚告訴各家搜索引擎,網站中有哪些網頁並不是要給讀者的,如此一來,提高了網路讀者的使用者體驗,同時也增加搜索引擎收錄效率。以Goggle為例,www全球資訊網這麼多網站網頁,如果能預先知道哪些沒有必要收到圖書館中,大大減輕館員工作負擔,利己利人。
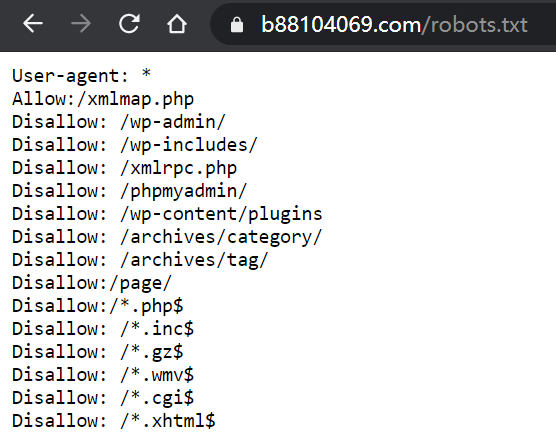
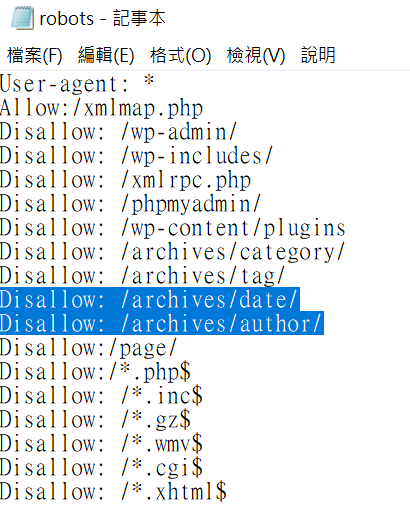
robots.txt文件必須放在網站入口、亦即網站根目錄,沒有架過網站的讀者,把網站想成電腦資料夾、網頁是資料夾裡的文件,應該會比較容易理解。截圖是贊贊小屋網站範例,第一次看可能難以理解,同樣以電腦文件,Windows裡面有很多系統文件和使用者操作無關,網站也是如此,可想見會有很多網站運作有關的程式文件,這裡很多的「Disallow:」就是要避免這些技術被Google收錄為www網頁,類似於Windows系統隱藏文件的效果。
六、Search Console說明
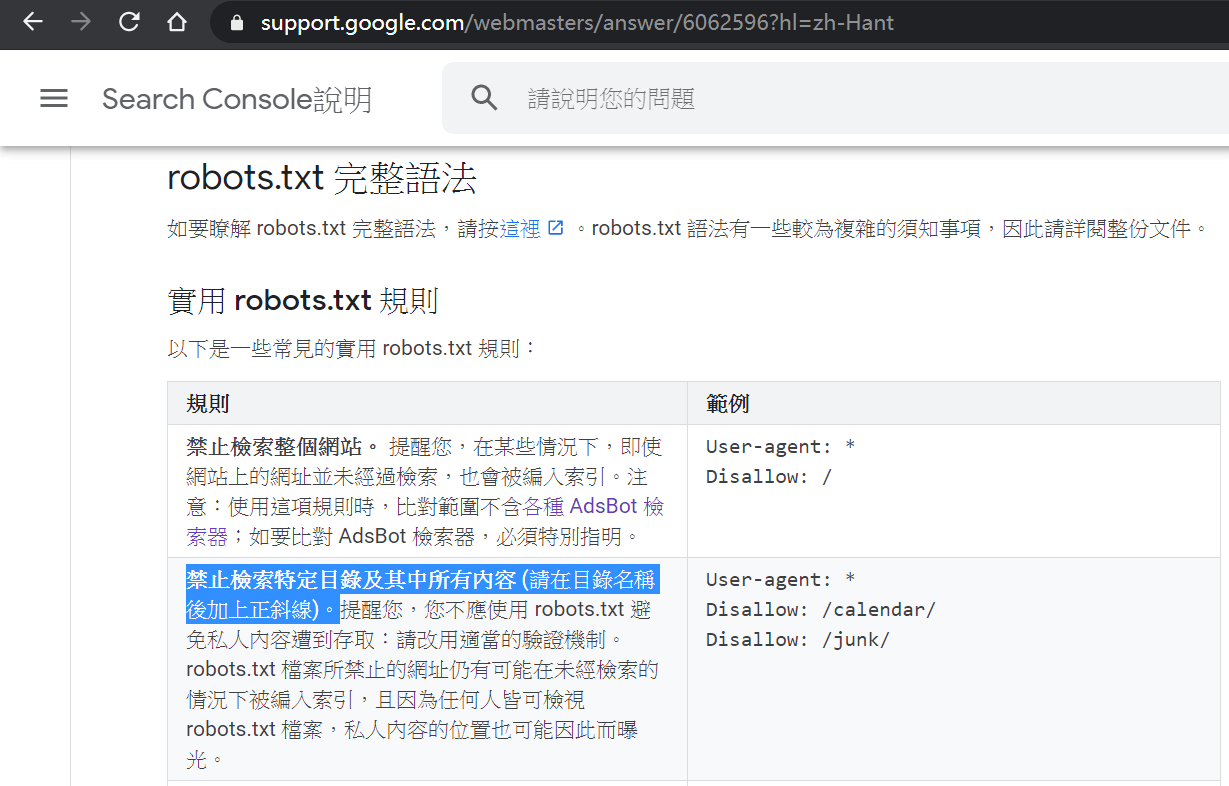
由於對雙方有利,Google在Search Console說明中心提供很多robots.txt的說明文件,具體到完整語法和示例語句,有興趣讀者可以參考。
七、遭到robots.txt封鎖
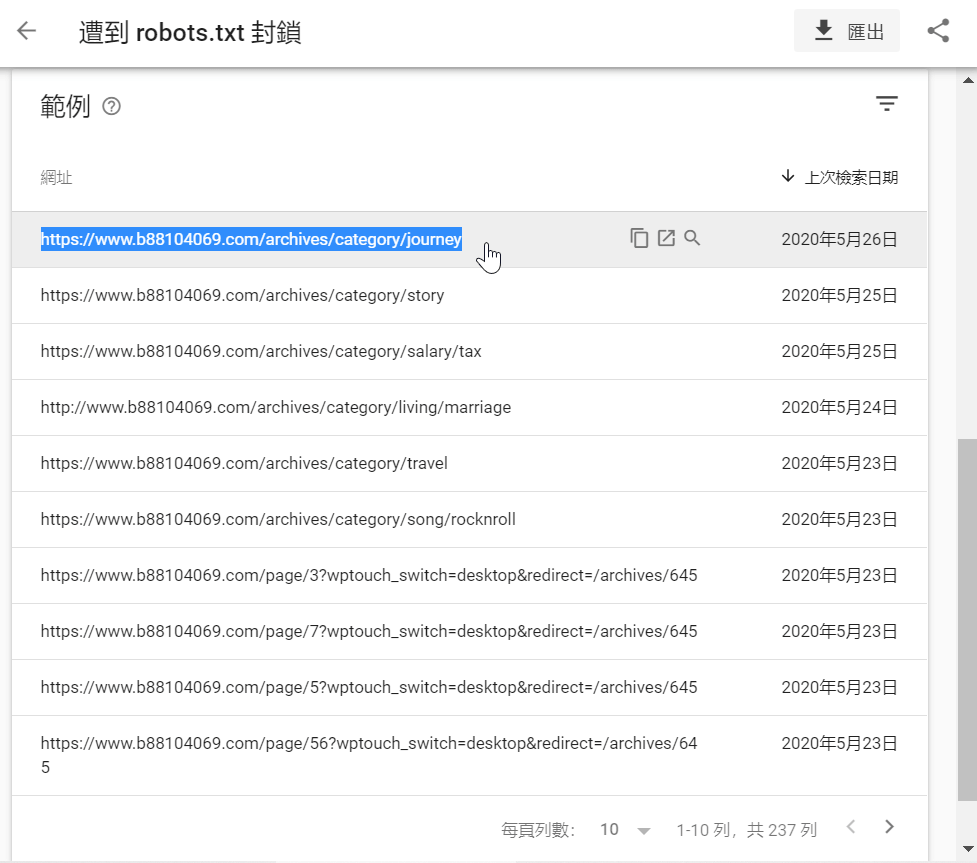
到這裡已經基本瞭解robots.txt文件,回到第一步驟涵蓋範圍中有個「排除」,有2976個之多,其中237個是被robots.txt文件擋掉的網站文件,可想見如果沒有robots.txt的話會很麻煩。
以第一個被排除的網頁為例:「https://www.b88104069.com/archives/category/journey」,這是分類頁面的網頁,參照第五步驟的「Disallow: /archives/category/」,robots.txt的實際作用和如何設定應該很清楚了。
八、robots.txt的Disallow設定
終於到達本文最後步驟,依照Google Search Console的索引報告相對應修改robots.txt文件:「Disallow: /archives/date/」、「Disallow: /archives/author/」。
這篇文章出現了幾次Sitemap,從Google Search Console網站工具上便可知道SEO少不了Sitemap,以後在系列文章會再作介紹。另外在涵蓋範圍的報告中有很多類別,這篇文章是集中在robots.txt排除的部份,其他部份同樣留後往後的系列文章。
相關文章:
