
Excel VBA爬蟲:1個取得及整理HTML的完整範例
Excel VBA爬蟲分成3大步驟,先分析網頁HTML原始碼,程式取得文件資料,分析規則得到目標文字,本文以書籍排行榜為範例說明,介紹引用項目及陣列的用法。
先前章節的程式架構是先取得全部資料再標記刪除,其實在程式設計也可以在取得網頁時即精準設定所需資料,這會使用到另一種VBA網路爬蟲的技術。兩種技術各有適用的場,如果只有單一網頁,網頁上大部份資料都是所需要的,使用原先第一種,如果有很多網頁,各個網頁只需要取得其中某一小部份的資料,這時候使用第二種技術較為合適。本節即以取各個書籍的出版社及分類為例,介紹第二種技術。
一、檢視網頁原始碼
書籍排行榜已經有很多資訊了,可是有時候需要進入個別書籍頁面,才能得到統計分析所需要的補充資訊。例如這裡看到的書籍分類和出版社,便是排行榜沒有,必須要在書籍本身的網頁才有的資訊。
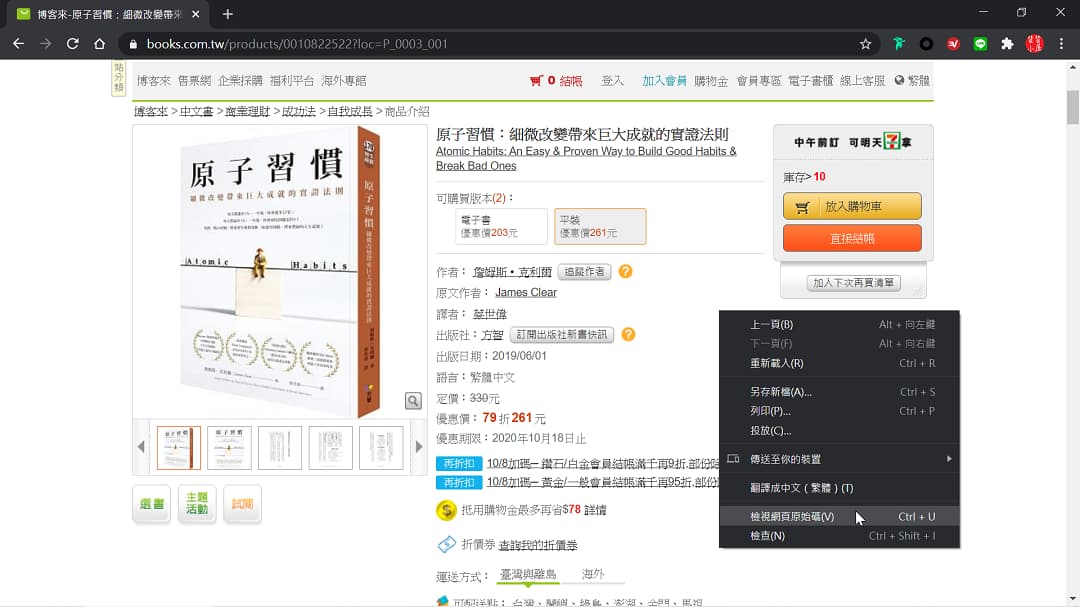
為了比較精准的取個網頁資料,有必要瞭解原始內容,所以在Chrome瀏覽器這個網頁上滑鼠右鍵,選擇「檢視網頁原始碼」。
二、html網頁原始碼
原始的網頁文件都是HTML語法,它是由一個個標籤所組成的,標籤格式分為成對與非成對,成對標籤的格式為「<標籤名稱>內容</>」,非成對標籤的格式為「<標籤名稱 屬性值=”…”>」。
例如截圖所示,出版社資訊是「<meta name=”description” content=”…”>」裡,分類資訊是在這兩個標籤裡面「<ul class=”container_24 type04_breadcrumb”>…</ul>」裡。
網頁HTML並非這本書主題,一本書篇幅有限,所以在此不再更細節的說明,讀者大概有個觀念就好了。
三、VBA設定引用ie
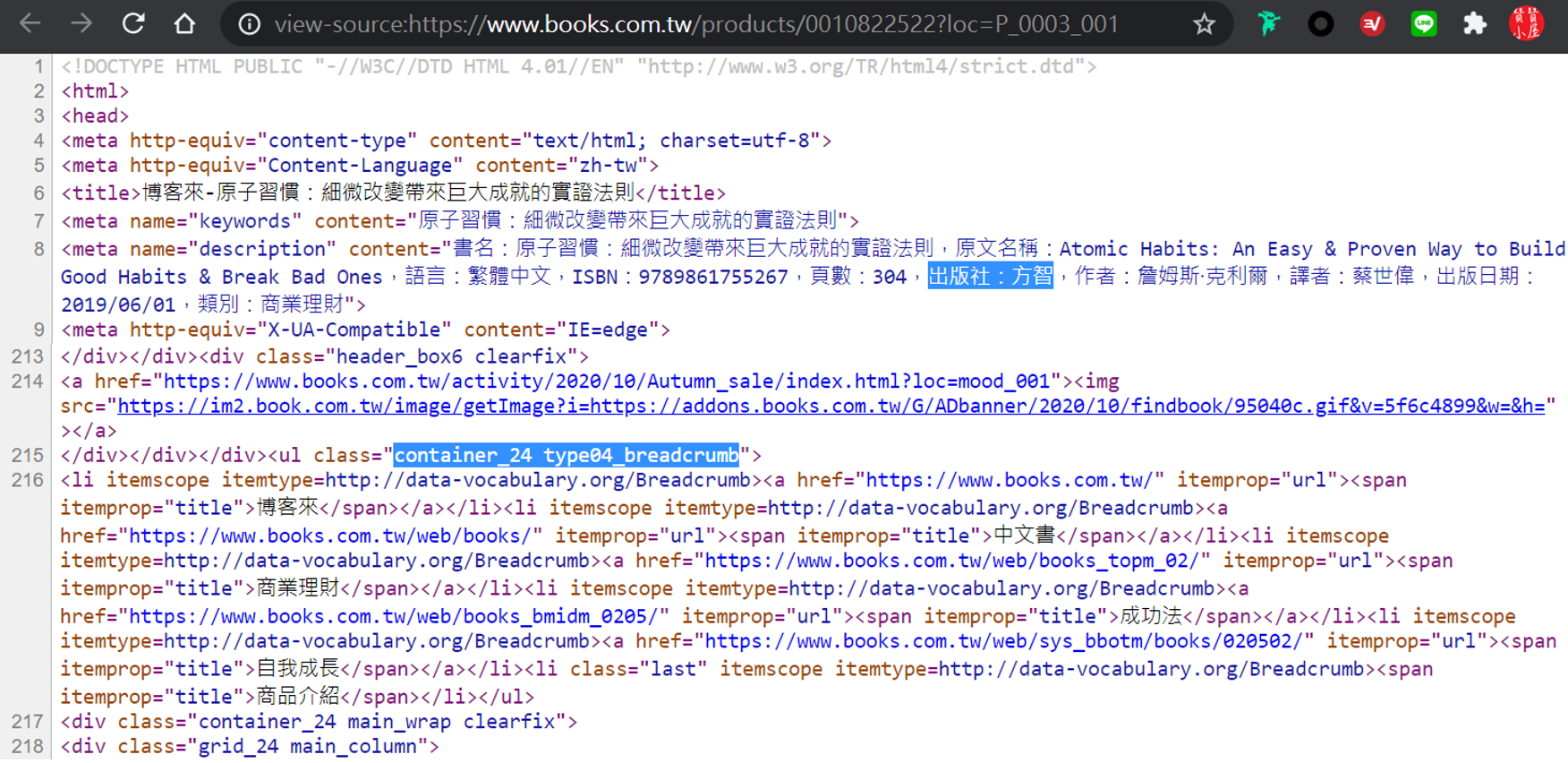
先前的VBA程式是使用Excel本身的取得網頁功能,接下來用另外一種方法取得網頁資料,也就是讓程式去開啟微軟的IE瀏覽器,再把瀏覽器所取得的網頁資料回傳給VBA,再寫入Excel。因此要開放VBA的IE外掛,在VBA編輯環境的上方指令列裡,點選「工具」裡面的「設定引用項目」。

四、Microsoft Internet Controls
在依照字母排序的清單裡面找到「Microsoft Internet Controls」,將這個項目勾選,按「確定」。注意到設定引用項目並不是統一設定的,是每個Excel檔案個別引用的,也就是雖然在這個檔案已經設定引用了,在其他舊檔案或新檔案要使用IE物件,必須再次把「Microsoft Internet Controls」設定為「可引用的項目」。
五、VBA ie爬蟲程式
程式分成兩個段落:
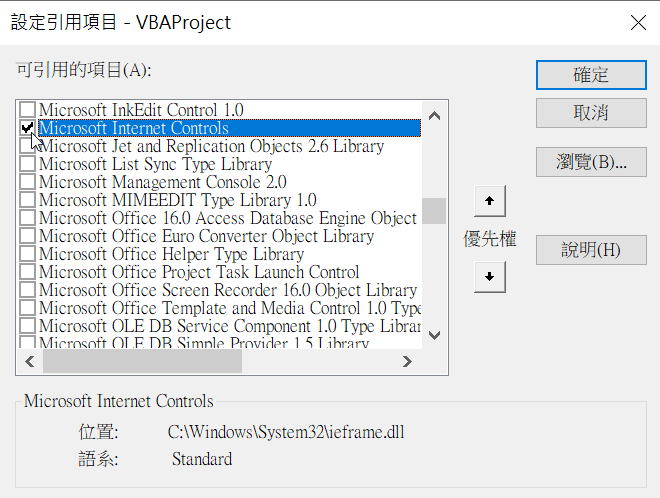
第一部份「取得網頁原始碼特定標籤文字」。建立一個微軟IE瀏覽器應用程式(InternetExplorer.Application),它在背後運作不顯現(Visible = False),瀏覽這一節第一步驟的網頁(Navigate),為避免出錯,設定為取得完整網頁文件再繼續下一行程式(Do Until…Loop)。
取得整個網頁原始碼後(With ExlIE.Document),擷取其中摘要的部份(WebTxt),這裡先取得所有「TagName」為「meta」的標籤集合,再限定其中的「description」標籤項目,「outerhtml」意思是連同標籤文字本身也要。最後關閉瀏覽器(ExlIE.Quit),結束VBA引用IE的狀態(Set ExlIE = Nothing)。
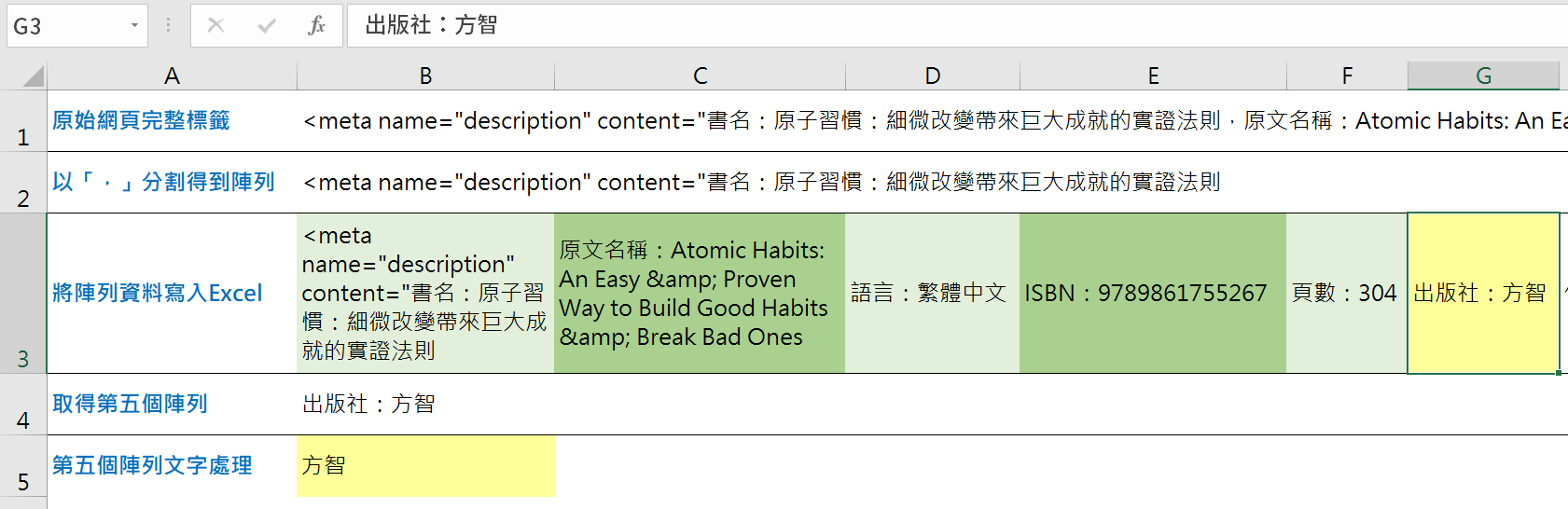
第二部份「處理所取得網頁標籤文字」。宣告兩個變數逐步處理並寫入Excel儲存格,先以「,」將網頁文字分割(Split),這樣會取得多個項目的陣列資料,把整個陣列分別寫入單一儲存格(Cells(2,2))和儲存格範圍(Range(“B3:L3”)),這樣會比較清楚陣列的多項目特性,接著取得陣列中的第5個項目(BookDes(5)),最後項目中不必要的文字「出版社:」以空白取代,等同刪除的作用(Replace)。
六、VBA html原始碼
執行程式後,在工作表上可以依序看到取得的資料內容,第三列是前5個陣列值,最終整理得到出版社「方智」。
七、VBA陣列文字處理
程式同樣分成兩個段落:
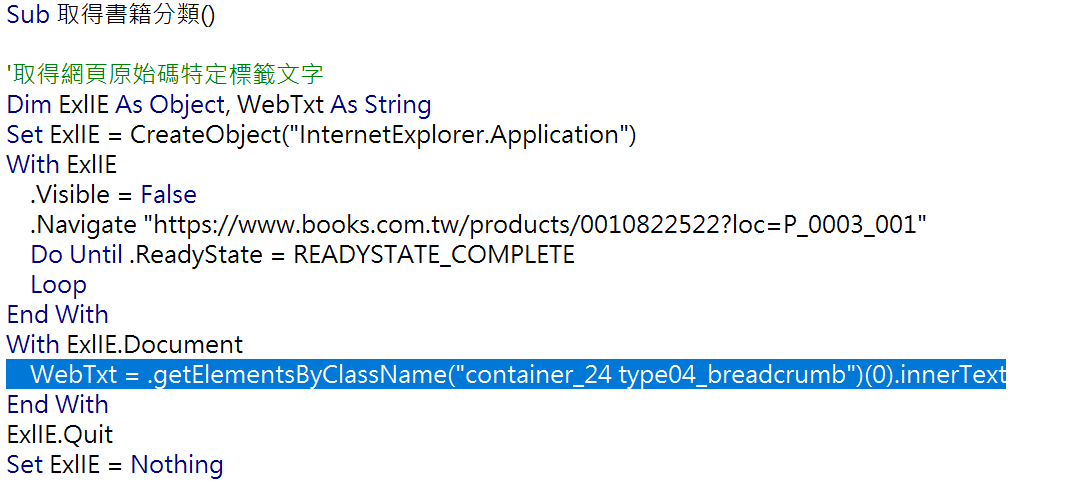
第一部份「取得網頁原始碼特定標籤文字」。程式架構和第五步驟相同,差別在於取得的標籤不同(getElementsByClassName(“container_24 type04_breadcrumb”)(0).innerText),利用「ClassName」限定某一名稱標籤集合後,因為該網頁應該只有這麼一個標籤,再設定「(0)」取得第一個標籤項目,最後是以「innerText」取得標籤內容文字即可。這裡和第五步驟相比較,會更加瞭解取得網頁標籤資料的語法。
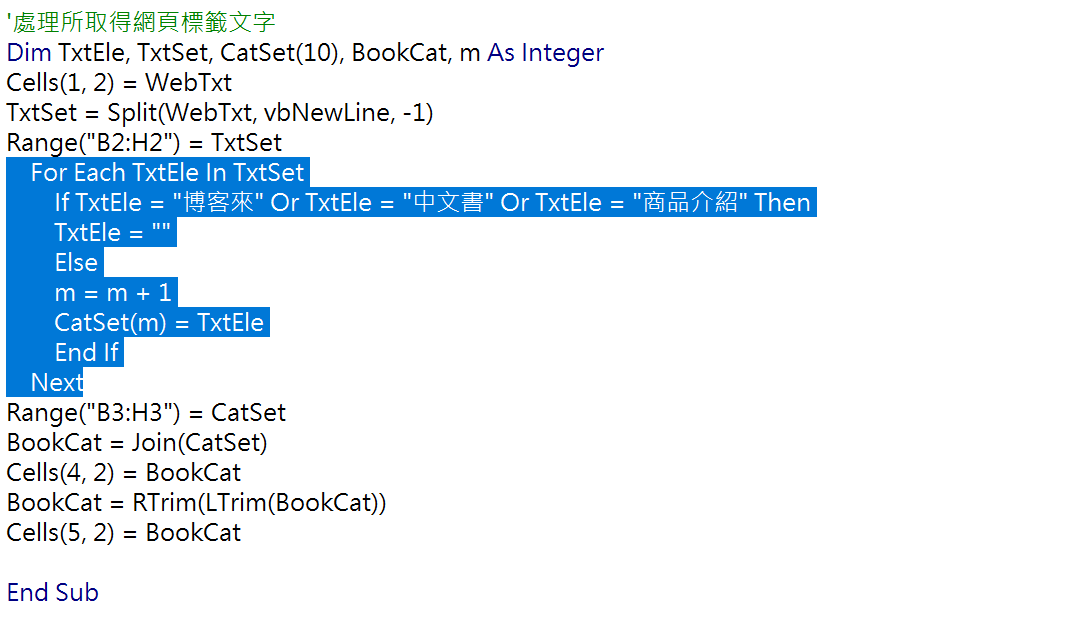
第二部份「處理所取得網頁標籤文字」。同樣先宣告變數,這裡比較特別的是「CatSet(10)」,表示是有10個項目的陣列變數。
Split(WebTxt, vbNewLine, -1):有三個參數,分別是要分割的文字,由於這幾個陣列值在網頁中有換行符,所以是用VBA裡的換行指令「vbNewLine」分割,第三個參數「-1」表示所有子字串都要傳回,這個也是因應網頁特性設定。
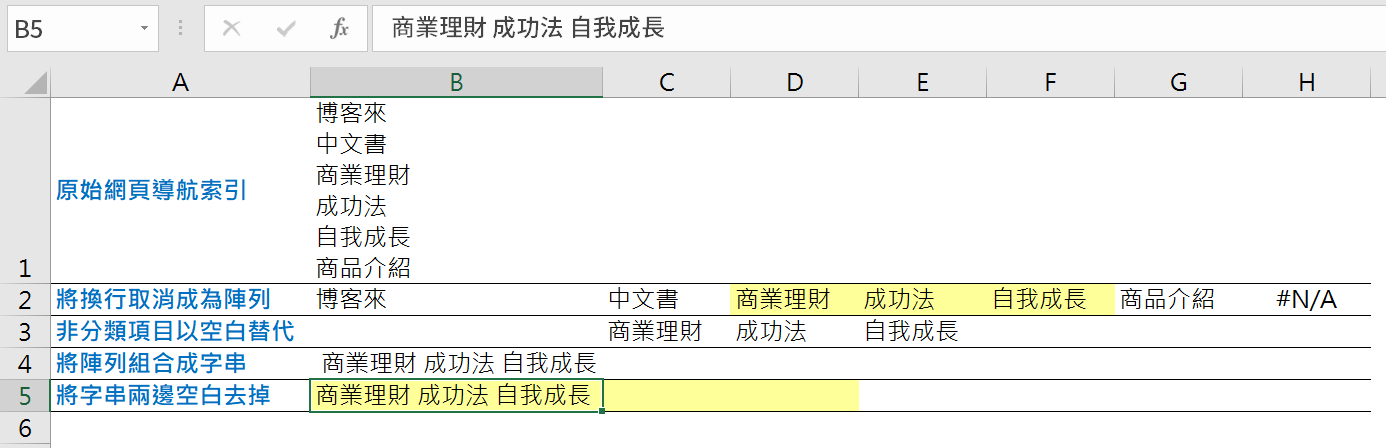
由於網頁是分類導航的形式呈現,同時會帶有不並所需要的分類項目文字,因此利用迴圈事件,針對原始網頁分類集合的每個項目(For Each TxtEle In TxtSet),如果是「博客來」、「中文書」、「商品介紹」(If…Then),把這些項目設定為空格(TxtEle = “”),遇到真正的分類文字時(Else),先以m紀錄有幾項(m = m + 1),再把這些真正的分類項目寫入新的集合(CatSet(m) = TxtEle)。
得到精準的分類集合後,先以Join函數將集合各項連結在一起,另外由於先前程式將不想要的分類項目設定為空格,這裡再以LTrim和RTrim將兩邊的空格刪除掉,最終得到以空格隔開的分類項目。
八、VBA網路爬蟲
同樣在執行程式後,在工作表上可以依序看到取得的資料內容,最終得到書籍分類「商業理財 成功法 自我成長」。
VBA ie爬蟲與陣列文字處理
這一節主要用到IE外掛物件和陣列資料處理,這兩項都是相對進階的VBA程式設計,讀者在一開始看到這些程式也許會感到陌生。不過程式都是簡單邏輯和簡單英文,經過本節講解應該至少能看懂這些程式碼,能應用在和這一節類似架構的網頁上,但如果要能活用到其他的網路爬蟲上,還是需要有紮實的VBA程式基礎。本書著重於取得資料進行分析,VBA程式知識不多作探討﹐有興趣請參考贊贊小屋其他相關著作。
完整VBA課程:職場及投資應用,20小時入門進階:
相關文章:
