VBA Chrome網頁原始碼會更清楚Html結構,有助於設計爬蟲程式,本文介紹如何檢視文件,看1遍讓你的爬蟲更有效率,同時補充專案開發必備的跨檔案複製模組。
票房排行、銷售排行、關鍵字排行,在網頁上常常會看到各式各樣的排行,這些排行是各個組織將原始資料以電子形式保留,並且加以統計分析的結果。上一章介紹如何以VBA程式碼同時取得多個網頁資料,在這一章以此為基礎,同時取得不同期間的排行榜資料,進一步彙總分析。
一、清華大學圖書館
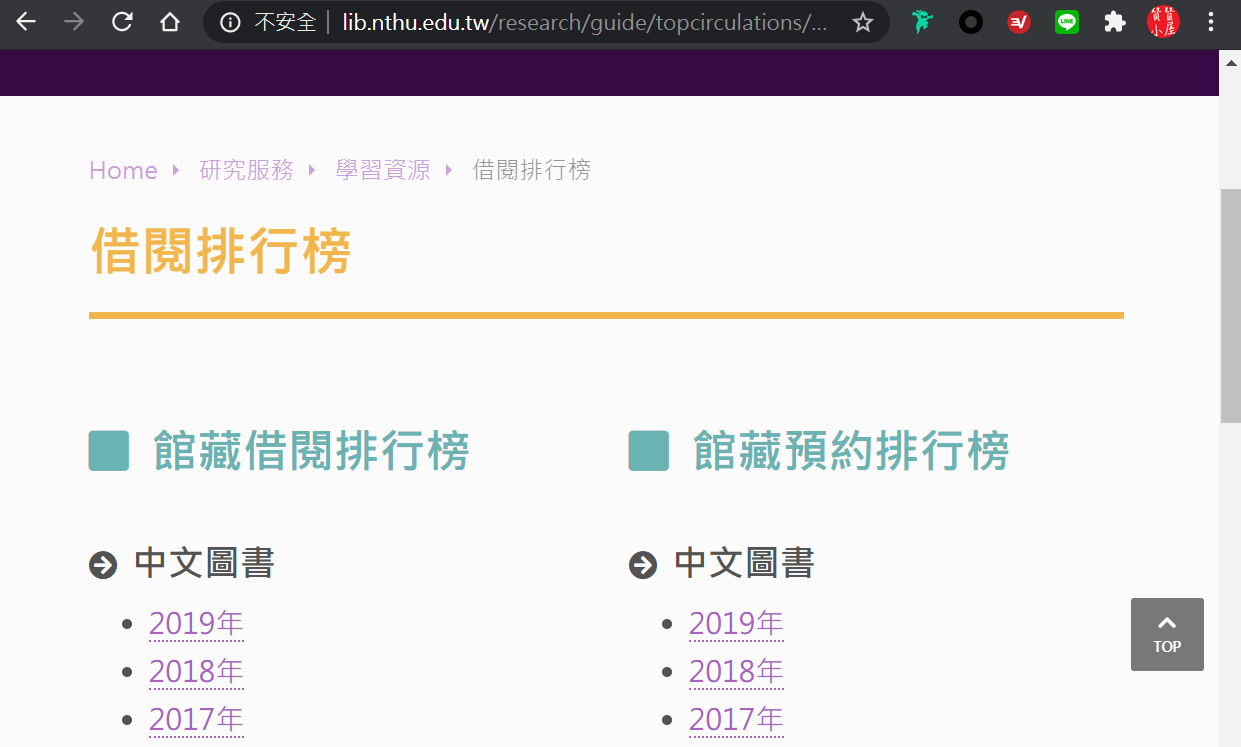
清華大學圖書館不但館藏豐富,常常舉辦文藝活動,網頁建置也非常完善,還有一個頗具特色的借閱排行榜。
二、程式碼複製貼上
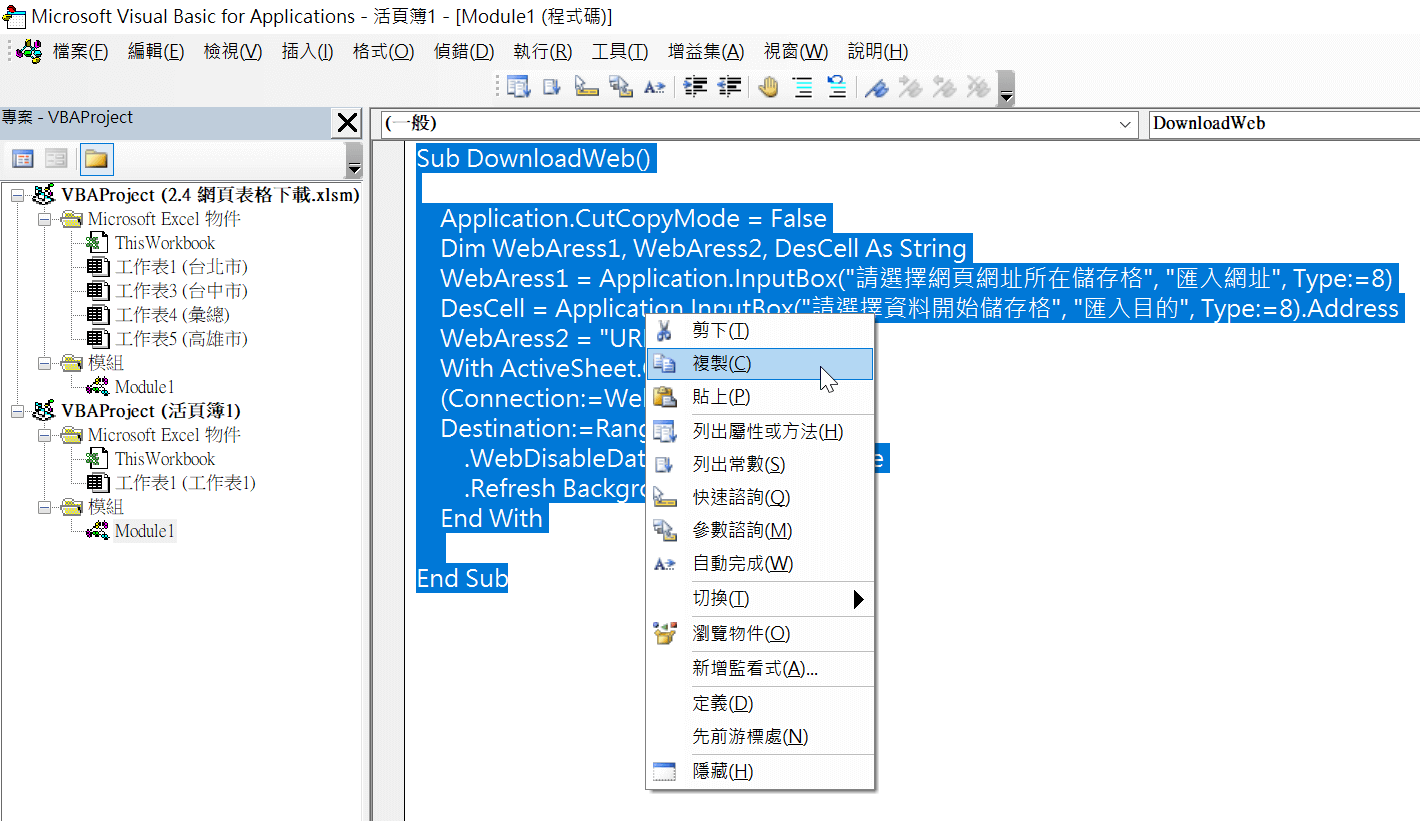
新建一個Excel活頁簿,利用第二章第一節「程式匯出匯入」所介紹方法,匯入第二章第四節「網頁表格下載」的巨集程式碼「Module1.bas」。不過如圖所示,同時開啓兩個Excel檔案,在VBA編輯界面左邊的「專案-VBAProject」視窗中,滑鼠連按兩下想要操作的物件(Module1),右邊便會跳出相對應的程式編寫視窗,可以用很熟悉直接的電腦操作,輕鬆直接將程式碼「剪下、複製、貼上」。
三、執行巨集
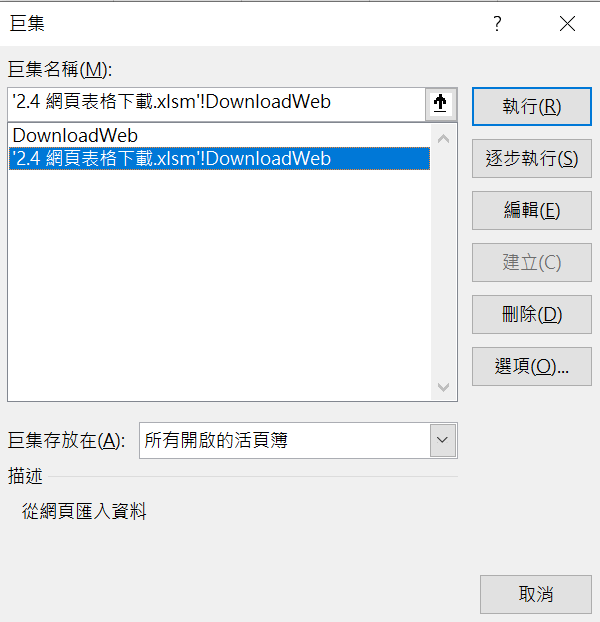
執行巨集,從圖片可以看出來,程式碼本身並沒有必然屬於哪個檔案、哪個活頁簿的限制,所以也可以選擇其他檔案的巨集程式,例如這裡是在新增的活頁簿直接執行「’2.4 網頁表格下載.xlsm’!DownloadWeb」。
四、WebSelectionType取得表格
執行結果,沒有取得任何資料,這是因為如同第二章第四節「網頁表格下載」所述,程式碼並沒有設定「WebSelectionType」屬性值,其預設值為「xlAllTables」,表示取得網頁上所有表格,表格以外的資料不取得。而這個網頁裡並沒有表格。
網頁的原始形式為HTML文本,有個簡單方式閱讀網頁的HTML文本,以Google的瀏覽器Chrome在網頁上滑鼠右鍵,「檢視網頁原始碼」。
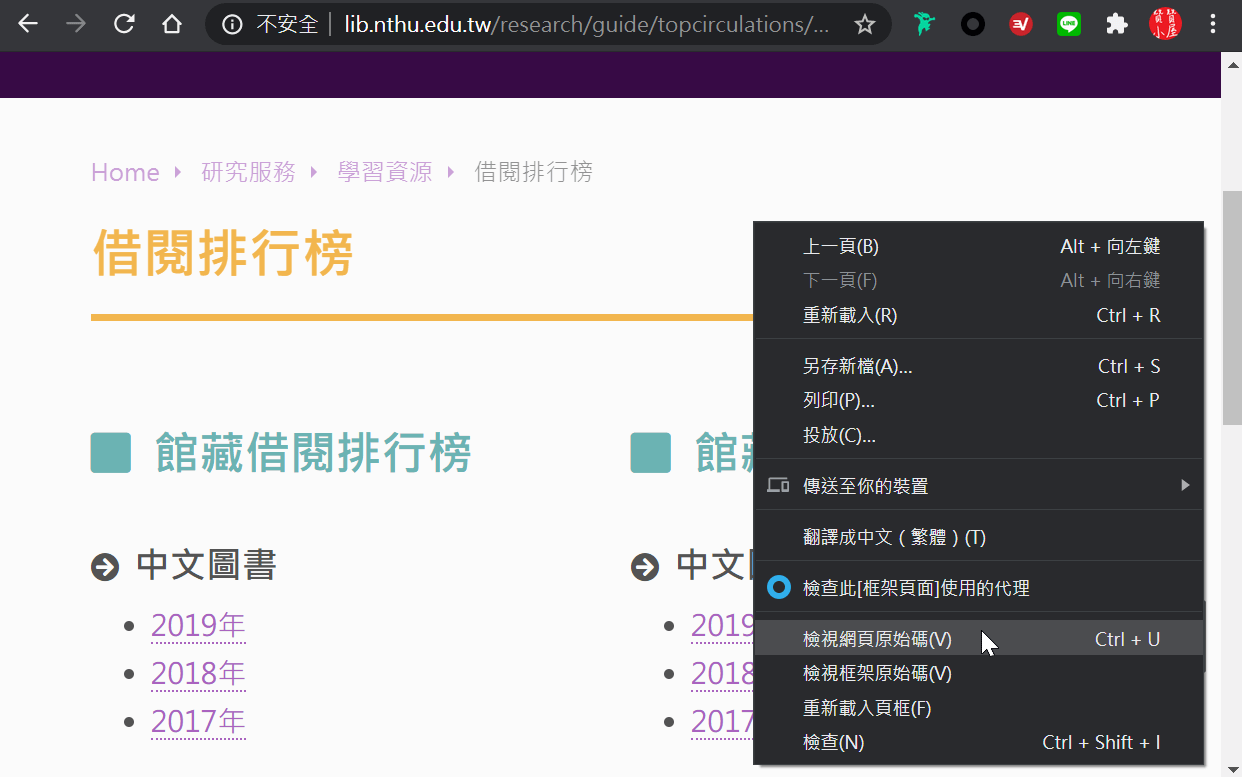
五、Google Chrome檢視網頁原始碼
Google Chrome會產生一個新網頁標籤,在原來的網址前面加一個「view-source:」,表示是檢視網頁原始碼。如圖所示,該網頁主要內容是由「<ul>、<li>、</li>、</ul>」構成的無排序項目清單列表,仔細從頭看到尾,並沒有任何表格資料。
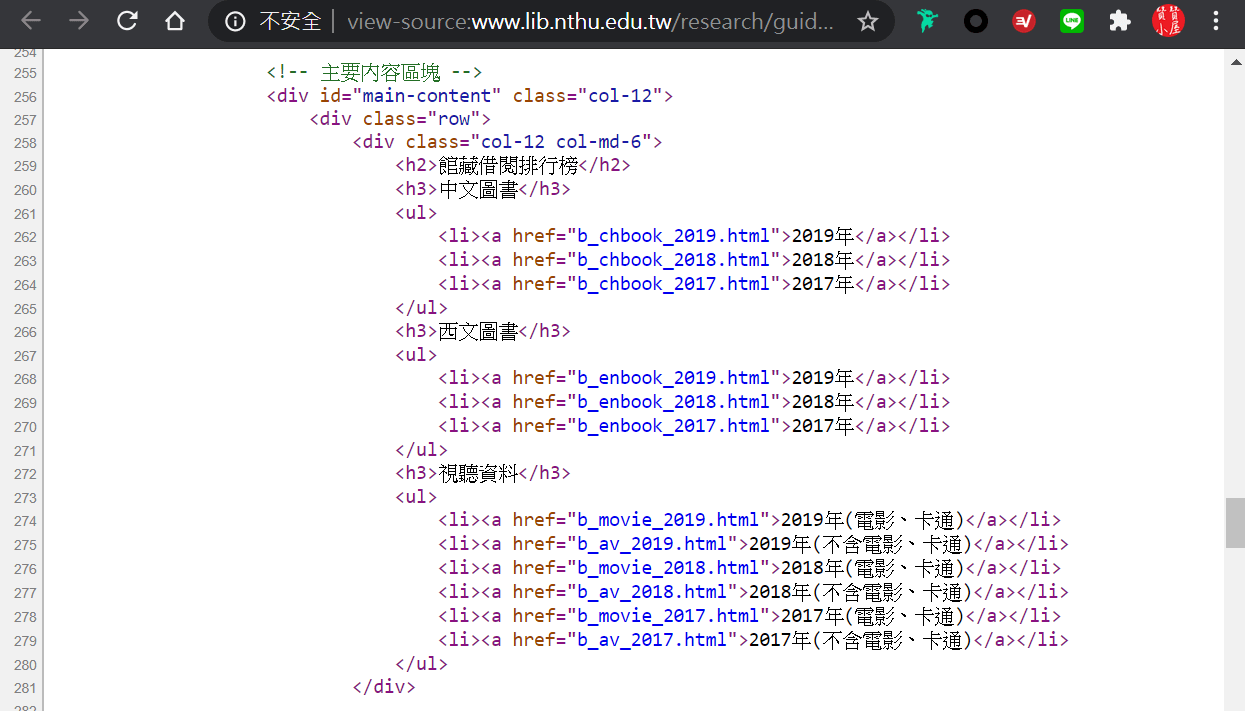
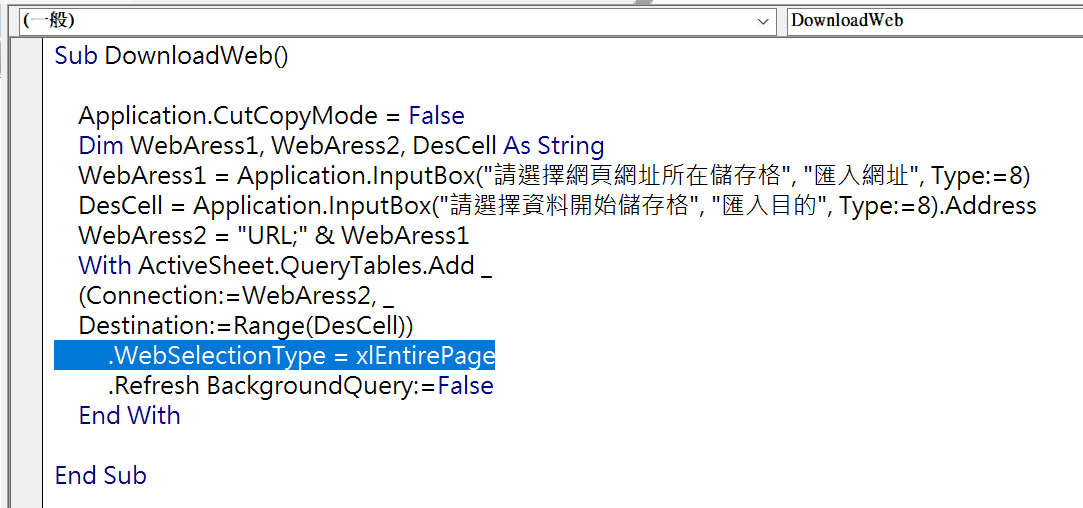
六、WebSelectionType = xlEntirePage取得全部網頁
瞭解原因後,VBA添加一行程式碼:「.WebSelectionType = xlEntirePage」,表示要取得網頁的全部內容,同時也將「.WebDisableDateRecognition = False」刪除。
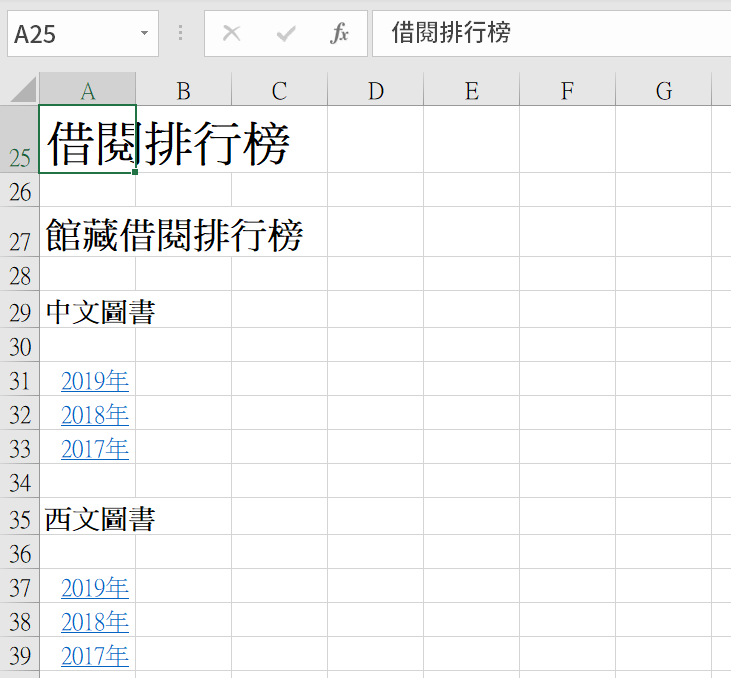
七、成功取得網頁
再次執行巨集,成功取得網頁資料。這裡並沒設置「.WebFormatting = xlWebFormattingNone」,因此資料格式同時下載啓用,原本的網址超連結同時也保留,例如滑鼠按一下「2019」,會跳出瀏覽器造訪「2019年中文圖書借閱排行榜」的網頁,相當方便。
HTML網頁知識與VBA網路爬蟲
這一節文章主要介紹只要同時開啓活頁簿,很方便可以進行VBA代碼的剪貼,也有提到HTML的基本概念,列表清單(UL)和表格資料(Table)是兩個網頁主要的資料形式,既然是利用Excel取得網頁資料,如能稍微具備HTML知識會更加得心應手。假使在Excel取得網頁資料遇到困難,建議可以利用瀏覽器檢視網頁原始碼的工具,瞭解網頁資料架構,搭配網路上豐富的HTML線上資源,也許問題便能迎刄而解。
本文章相關影片:

贊贊小屋VBA教學中心:
Excel巨集錄製教學、Excel巨集程式、VBA編輯器、VBA自學入門、VBA基礎語法、VBA基本應用、VBA UserForm、VBA VLOOKUP。
VBA課程推薦:零基礎入門進階的20小時完整內容